Cryptography is a way of encoding and decoding information to guarantee its confidentiality and protection from unauthorised individuals. Within the realm of digital security and cryptographic algorithms, digital signatures play a critical role in establishing trust. Analogous to a physical signature, digital signatures leverage cryptographic algorithms to generate a unique mathematical fingerprint linked to the message content. Though software implementations of cryptographic algorithms are possible with general-purpose processors which usually excel in typical applications, yet they lack efficiency in performing complex arithmetic calculations, particularly those employed in cryptography as they have a maximum word length of 64 bits. The current guideline for the key length in cryptographic systems like RSA and Diffie-Hellman is greater than 2048 bits.
RISCV-128 coprocessor to the rescue
The emergence of 128-bit architectures has sparked a profound debate within the realm of cryptography, prompting researchers to contemplate the potential impact of this technological advancement on secure communications and data protection systems. A crypto coprocessor that possesses the ability to execute their software accurately, even when subjected to physical attacks facilitate a wide range of applications by executing diverse cryptographic functions, including key distribution, key management, digital certificate management, encryption, and decryption.
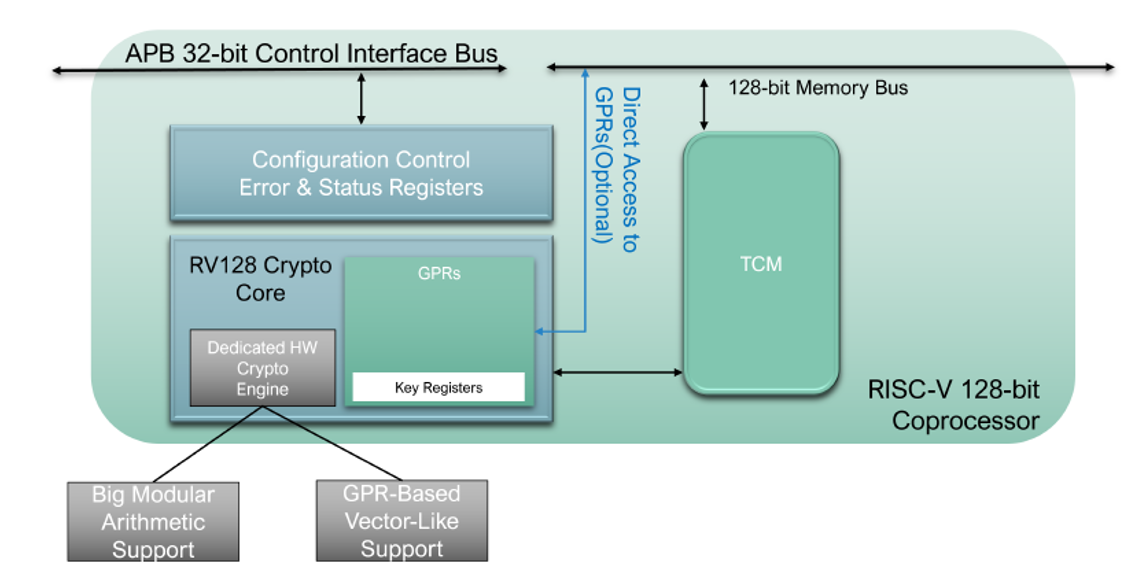
The proposed design of the RV128 Cryptographic Coprocessor as portrayed in the above figure, integrates several components for efficient cryptographic computations and secure key management. The modular structure ensures flexibility and ease of integration into various systems requiring cryptographic acceleration. The Dedicated Hardware Crypto Engines are internal units within the Crypto Core, designed to execute cryptographic algorithms efficiently. It operates within the heart of the coprocessor, specializing in handling various cryptographic functions that include symmetric and asymmetric cryptography. The Crypto Engine handles ECC with the Big Modular Arithmetic Support unit for secure data encryption-decryption and hashing algorithms like SHA-2 and SHA-3 with GPR-Based Vector-Like Support.
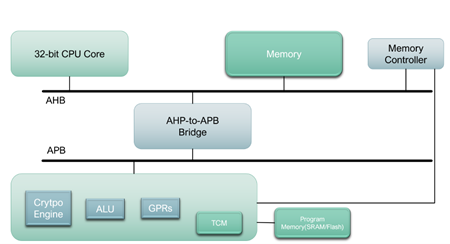
The system-level architecture as proposed in the above figure outlines the integration of a 32-bit CPU with a dedicated cryptographic coprocessor. Integrated within the 32-bit CPU is a specialized decoder that actively identifies cryptographic operations embedded within the software. These computationally intensive tasks are then strategically offloaded to a dedicated cryptographic coprocessor for accelerated processing. The 32-bit CPU seamlessly interacts with the coprocessor via the AHB, with the AHB-to-APB bridge serving as a vital intermediary for data and control signal transfer.
Customization with Codasip Studio
With Codasip Studio as the development platform, it is much easier and more convenient to explore the potential benefits of custom instructions for cryptographic algorithm optimization within the RISC-V architecture. This is because the tools are capable of generating a compiler, a software toolchain, and verification components directly from the CodAL description. This means, custom instructions can be interpreted directly by the compiler from the C-code, integrating smoothly into the development workflow. It’s important to note that, at the current time, none of the existing RISC-V simulators offer native support for the RV128 instruction set variant and hence this approach would involve utilizing data and instruction formats from existing RV32 or RV64 simulations and extrapolating them to represent RV128 behavior.
Custom instruction for Montgomery Multiplication
The main aim of introducing this custom instruction is to have dedicated hardware within our crypto engine to optimize the unique demands of Montgomery multiplication, further reducing the CPI, which is the core measure of instruction efficiency.
To benchmark the newly introduced custom introduction, the conventional modulo operator % for Montgomery multiplication is compared against montred for the same operation. There was substantial reduction in code size observed from 24.5kb to 18.8 kb suggesting improved memory efficiency and faster loading times with montred.

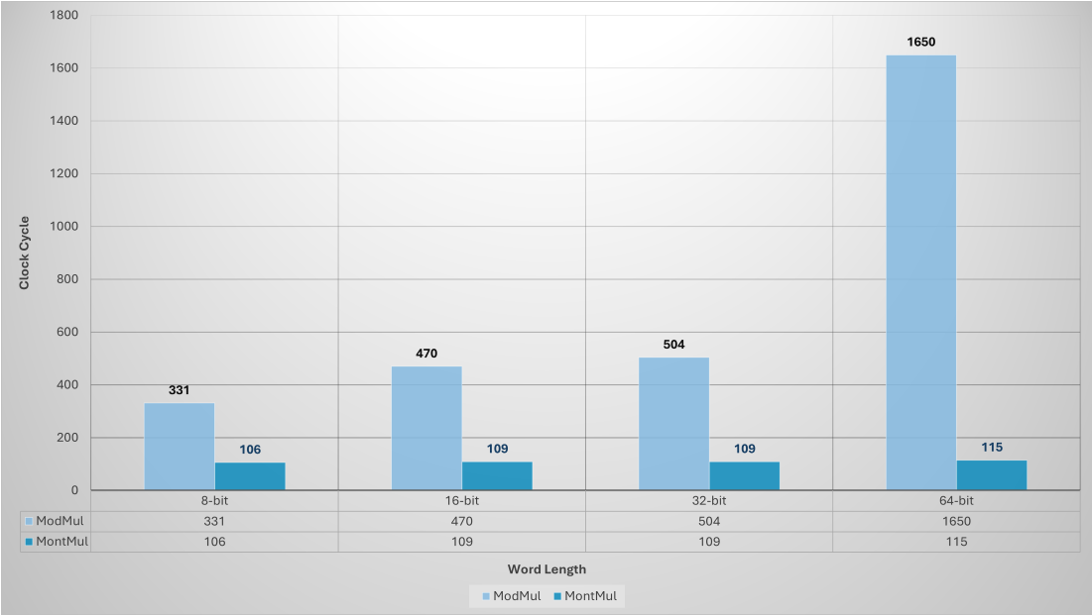
From the column-based chart, it is clear that MontMul achieves a remarkable 93.03% gain in performance compared to ModMul with 64-bit operand.
Benchmarking Montgomery scalable algorithms with custom instructions
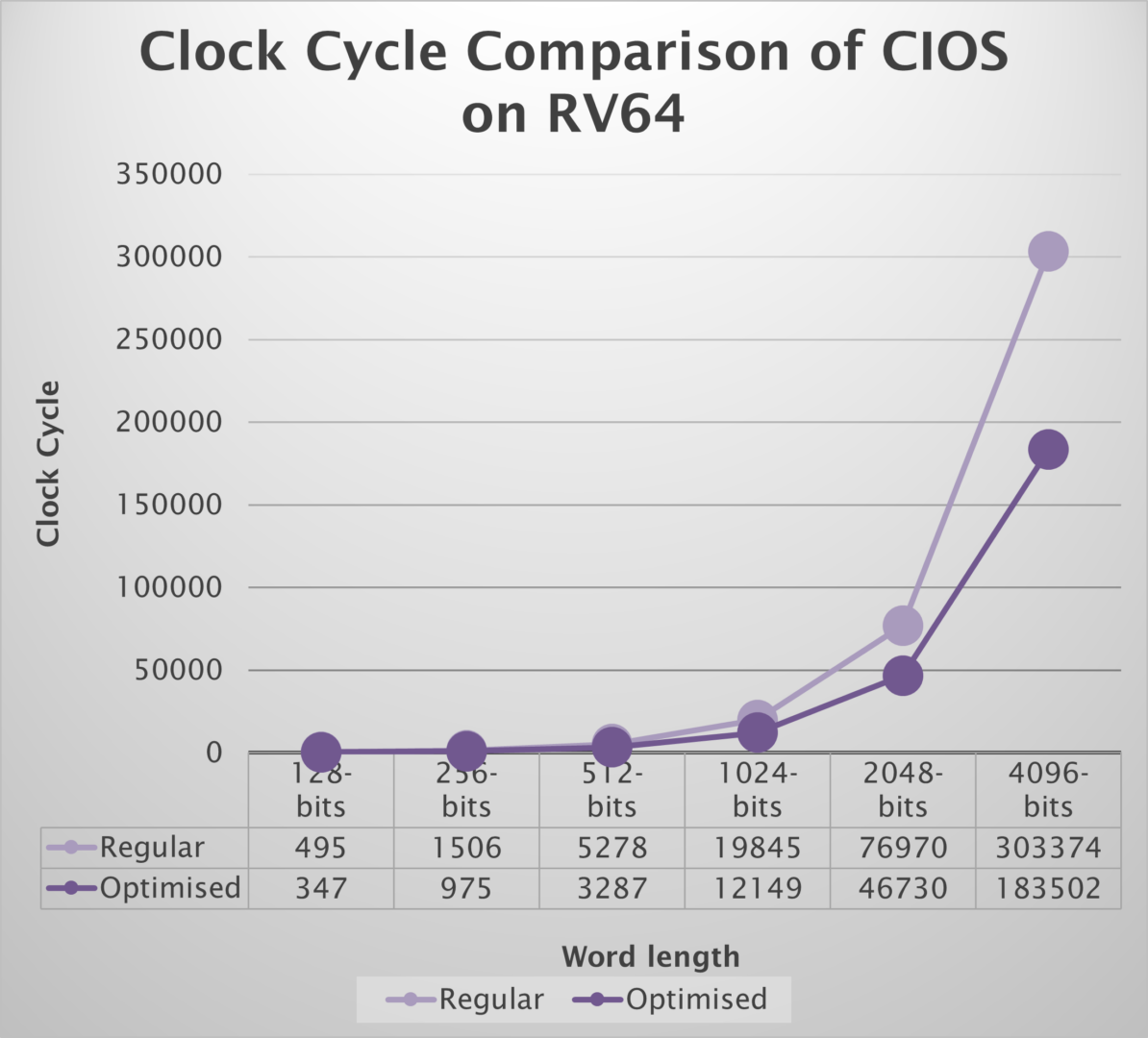
The graph portrayed above presents a comparative analysis of clock cycles required for the CIOS algorithm on the RV64 architecture. The data emphasizes the significant clock cycle reductions ranging from 30% to 39% across various operand sizes by incorporating custom instructions, namely ADDC and MACC.
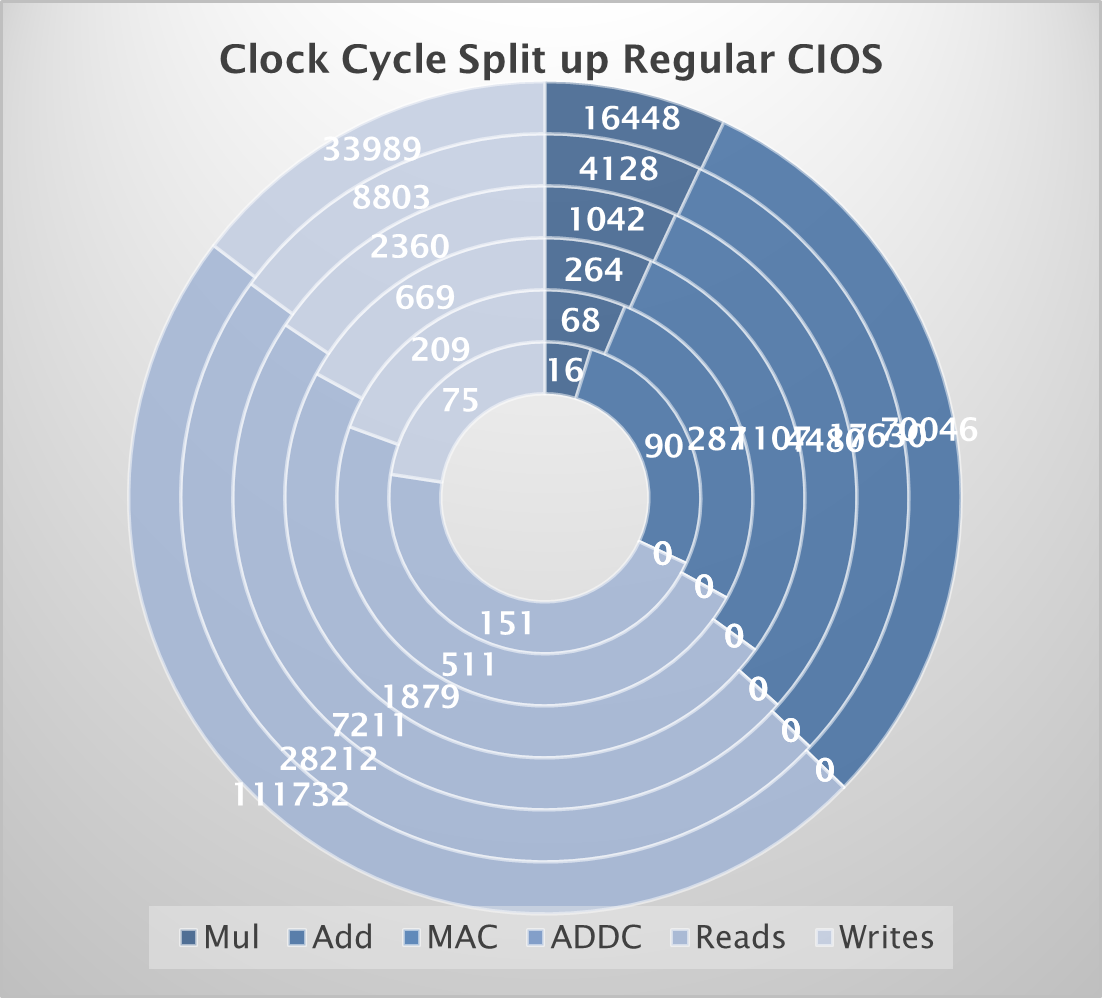
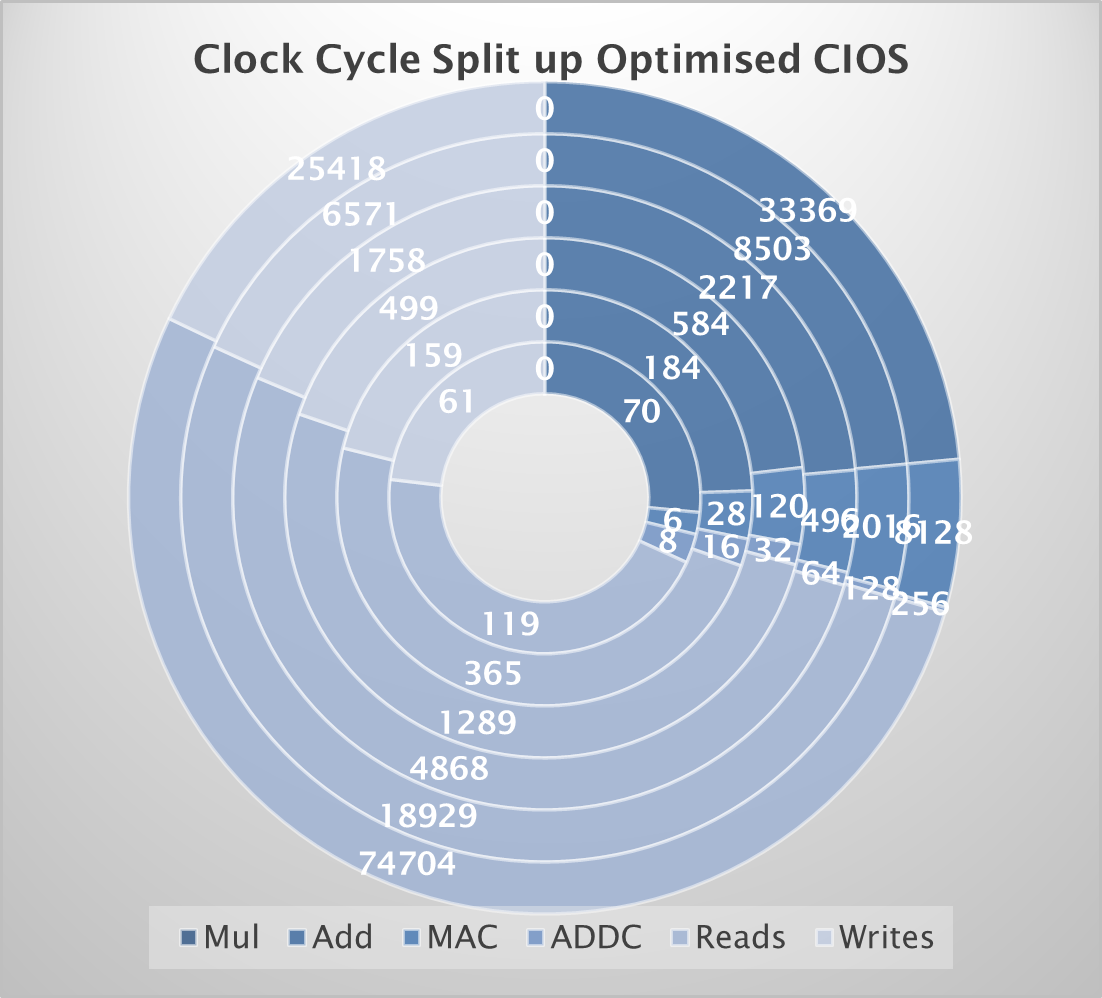
Through a series of doughnut charts as shown above, a detailed breakdown of clock cycle allocation for the CIOS algorithm with and without custom instructions (ADDC and MACC) was captured for fine-grain analysis. The baseline implementation reveals addition as a major bottleneck, consuming around 18% of clock cycles at 128-bits. Memory read/write operations also contribute significantly, accounting for 30% and 15% of cycles, respectively. The optimized implementation significantly reduces the number of addition cycles, with a 23.3% decrease at 128-bits. MACC cycles increase with operand size, highlighting its role in consolidating multiplication and addition. While memory access patterns remain largely unchanged, the optimized implementation demonstrates a substantial performance improvement due to the efficient handling of arithmetic operations by the custom instructions.
Keccak function analysis with custom instructions
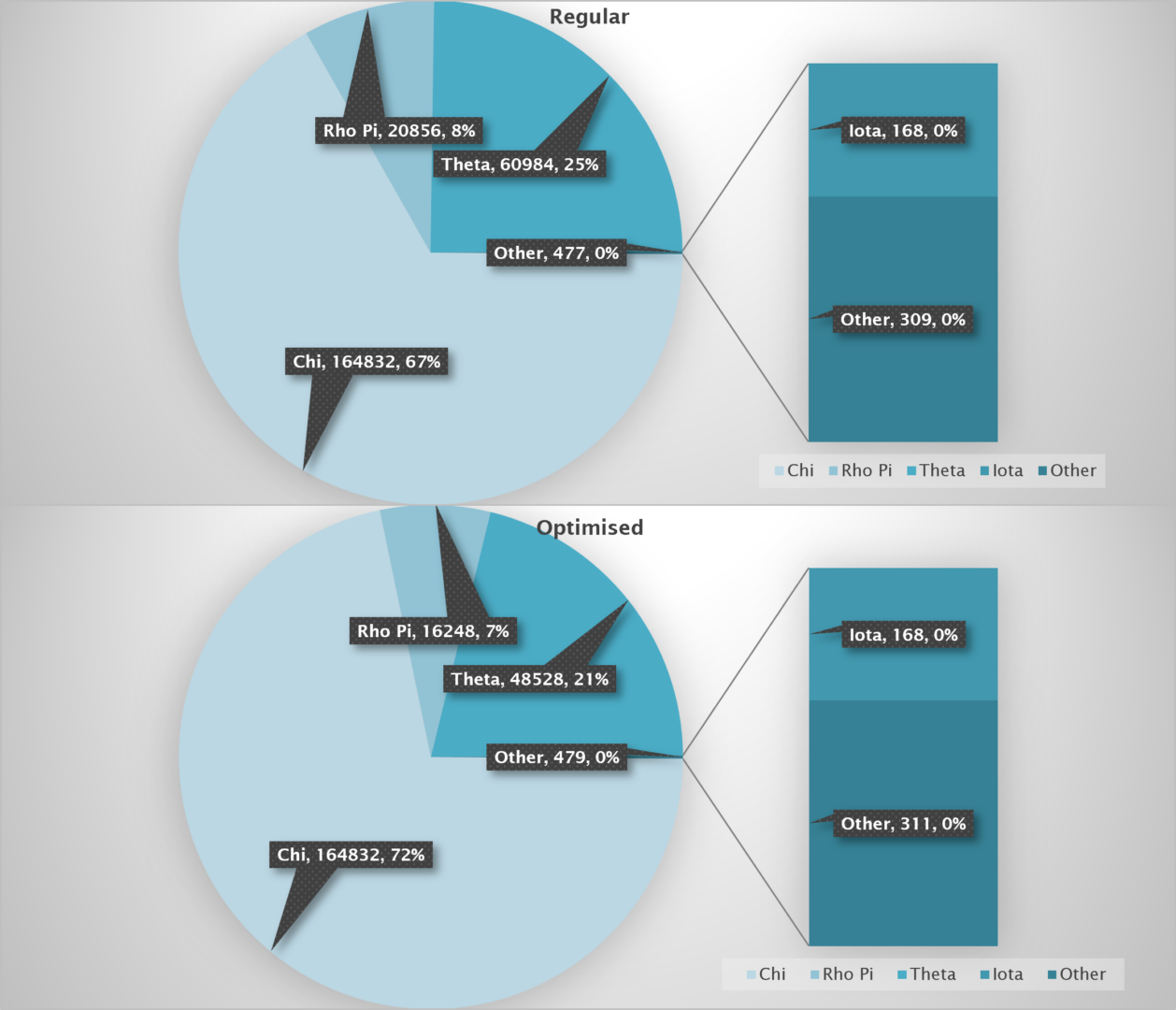
The above pie-charts illustrate a 7% performance improvement in the Keccak function using custom instructions (vROT and vXOR). The optimized implementation reduces clock cycles by 17,062, with a 20.4% improvement in the Theta step attributed to vROT and a 22.1% improvement in the Rho Pi step due to streamlined operations.
Conclusion
The proposed RV128 coprocessor offloads cryptographic workloads from the main CPU thus enhancing system efficiency. The study investigated the performance gains in wider RISC-V architectures and successfully demonstrated the advantages of larger word space. Considering comprehensive RISC-V ISA support, seamless integration with the RISC-V architecture, support for custom instruction development, and profiling, Codasip Studio stood out as the ideal software IDE for this research work.
