The area of any part of a processor design contributes both to the silicon cost and to the power consumption. A simplistic following of the “A” in a processor IP vendor’s PPA numbers can be misleading. A processor is never used in isolation but is part of a subsystem additionally including instruction memory, data memory, and peripherals. In most cases, instruction memory will be dominant and the processor area is much less important.
What impacts the size of the instruction memory in a processor?
The size of the instruction memory will be influenced by the target instruction set, the compiler and the compiler switches used. In the case of RISC-V, the choice of optional standard extensions and custom extensions can greatly influence the codesize.
Instruction set and processor memory: the example of Microsemi
To illustrate this, the following table shows the effect of adding extensions to both core and codesize.
| ISA | Core size (kgates) | Increase over base | Codesize (kbytes) | Decrease over base |
| RV32I (base) | 16.0 | × 1.0 | 232 | × 1.0 |
| RV32IM | 26.2 | × 1.6 | 148 | × 1.6 |
| RV32IM+DSP | 38.7 | × 2.4 | 64 | × 3.6 |
Source: Implementing RISC-V for IoT applications, Dan Ganousis & Vijay Subramaniam, DAC 2017
In this example, Microsemi used a Codasip RISC-V L31 processor to implement an audio processing application. Starting with just the 32-bit base instruction set, they had an unacceptably high codesize and cycle count. Some improvement was achieved by adding multiplication [M] extensions, but the breakthrough was using custom DSP instructions. These led to a 3.6× reduction in codesize at the price of a 2.4× increase in core size compared with the base core. With instruction memory dominating the area, this was a good trade-off; furthermore, the performance goals were readily achieved.
Compilers, complex switches and PPA
With typical vendor PPA data, synthetic benchmarks such as CoreMark/MHz are often quoted with a complex set of compiler switches - this is something we discussed in our article dedicated to processor performance. But in practice, embedded software is probably going to be compiled using common switches such as ‑Os or ‑O3.
Consider compiling the CoreMark benchmark with different switches using the common GCC compiler. In this case, the target was a Codasip RV32IMC RISC-V core with a 3-stage pipeline.
The chart below shows CoreMark/MHz and codesize measures for different compiler settings. The last example is one that is typical of vendor performance data where many switches are used for CoreMark (CM = “-O3 -flto -fno-common -funroll-loops -finline-functions -falign-functions=16 -falign-jumps=8 -falign-loops=8 -finline-limit=1000 -fno-if-conversion2 -fselective-scheduling -fno-tree-dominator-opts -fno-reg-struct-return -fno-rename-registers --param case-values-threshold=8 -fno-crossjumping -freorder-blocks-and-partition -fno-tree-loop-if-convert -fno-tree-sink -fgcse-sm -fgcse-las -fno-strict-overflow”).
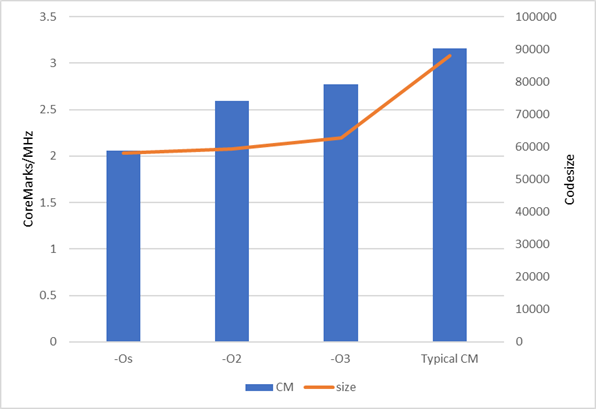
In this example, the CoreMark/MHz score grows as the switches change from left to right. However, it is interesting to note that the most complex set of switches increases the codesize by 40 % over ‘‑O3’ while the performance only improves by 14 %.
Not every example will behave in this way, but compiler switches influence both performance and codesize. It is important to be realistic about what compiler switches you would like to use, and to ensure that the switches for any performance benchmark data matches those you would use for assessing codesize.
The impact of PPA on your processor choice
PPA numbers will inevitably be used to compare processors. However, these indicators need context to be representative of your actual needs, and not be misleading. Some key considerations, including OS support and ISA choices, will also influence your processor choice. To find out more, read our white paper on “What you should consider when choosing a processor IP core”.
