Here at Codasip we’re passionate about reducing the code size of our RISC-V cores for our customers, but why? Are we not making the core larger and more complex as we add instructions to improve the situation? In short the answer is yes we are, any instructions added to the processor increase the size, complexity, and power dissipation and so there has to be a benefit to justify it. Let’s see, in this blog post, how to optimize your RISC-V code size.
Why you should consider reducing your code size
First, let me tell you why you should care about it.
Reason 1: Reduce the total system cost
For small embedded cores, the actual size of the processor is not so important when compared to the size of the SoC (including the Boot ROM), and the external flash memory. What we find is that adding, say, 1-3% to the size of the processor to add additional functionality can reduce the code size by up to 20%. This means that software fits into a much smaller ROM and external flash memory making the total system cost much lower, for a moderate increase in processor size and power.
Reason 2: Reduce power dissipation and increase performance
Reducing the number of bytes for a given program reduces the number of memory fetches required to fetch the code. This reduces the latency required, and therefore the power. Additionally this increases the performance as less time is spent waiting for cache misses to be serviced, or waiting for Tightly Coupled Memories (TCMs) to be filled by Direct Memory Access (DMA) engines for processors without caches.
I hope you are now clear on why you should spend some effort trying to minimize your code size, so let’s now look at how to do it.
Implementing the standard Zc extensions
The RISC-V Zc extensions, led by the Codasip team, were ratified in Q2 2023. If you feel like checking it out, here is the link to the released specification. If not, let me briefly explain what these are.
What are the Zc extensions?
The RISC-V Code Size Reduction Task Group that I chair came up with Zc extensions. The Zc extensions are part of the RISC-V standard compressed instruction-set extension, named “C”, which reduces static and dynamic code size by adding short 16-bit instruction encodings for common operations.
I recently presented a paper at the European RISC-V summit on RISC-V code size reduction with Zc extensions and dictionary compression custom instruction. Let me give you a summary here.
How the work started
Because it allows more code to fit in the instruction memory or cache, the RISC-V C-extension is extremely useful for code size reduction and performance improvements. RISC-V cores, especially for small devices that are cost sensitive (for example IoT devices), need more on-chip memory, or off-chip flash to store code, increasing system costs. Larger systems will have DDR or even HBM off-chip memory.
The Code Size Reduction Task Group has been working since 2020 to improve the situation by defining the Zc extensions. These extensions cover the range of RISC-V implementations from high-end application cores to microcontrollers.
The project scope
In the paper I presented, we assessed the effectiveness of the proposed Zc extensions by using a series of benchmarks to compare the code size with the C-extension.
The test cases were taken from Opus [1] and LP3 [2] audio codecs, CoreMark [3], Embench [4], FPMark [5] and Debian benchmarks among others. To eliminate compiler dependencies we used both GCC and LLVM. We assessed each group of Zc instructions along with a proposed custom instruction for dictionary compression. Full benchmark details are available online [6].
Let’s have a look at some optimizations, though the presented paper covered more. I might share this in a longer form article very soon. Stay tuned!
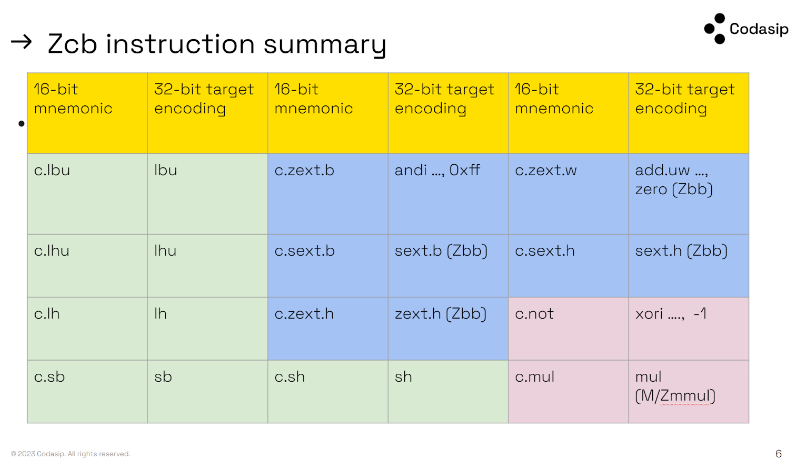
RISC-V Zc extension: Zcb
The Zcb extension is suitable for high-performance implementations, and is included in the RVA23 application profile, saving almost 1% code-size on average for almost zero implementation cost. Some Embench benchmarks benefit by 5-6% from this extension. For large code-bases 0.5%-2% is more typical.
All encodings are currently reserved, so it is compatible with the architecture profiles. It includes 12 encodings.
The instructions are all 16-bit versions of existing instructions from the architecture profile, so the cost is only 12 additional lines in the 16-bit instruction decompressor (if implemented) or 12 more lines in a combined 16/32-bit instruction decoder, mapping onto existing decodings.
The instructions expand to sign/zero extension, multiply, load/store of bytes and half-words and also not functionality (XOR with -1).
Dictionary compression / instruction table
Dictionary compression is an old technique where common patterns are replaced with a short index into a table or dictionary [7]. It is used in compression algorithms and has been applied to computer architectures for code-size reduction since at least the 1990s.
The idea behind this one is to have a table of micro-code in memory, and a 16-bit instruction which calls an entry into the micro-code. For the first version we are proposing a subset of the functionality: each micro-code sequence must be a single 32-bit instruction only.
Very similar to Zcmt / table jump - this first version allows a 16-bit encoding to expand to any 32-bit instruction (as opposed to expanding to any 32-bit function address). To avoid complexities with the PC, any 32-bit instructions in the table which are PC relative will be illegal on execution.
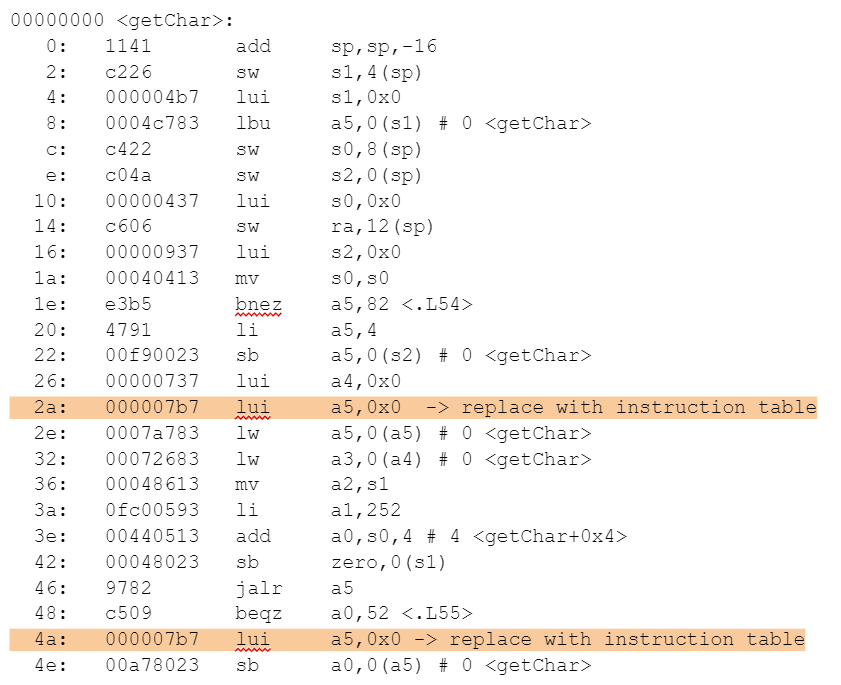
For example here is one function from the Embench benchmark picojpeg. We see that the 32-bit encoding for lui a5,0x0 is used twice, it is also repeated in other functions. Therefore we can allocate the encoding (000007b7) into the instruction table and so replace every usage with a 16-bit instruction which fetches the encoding from the table. This saves 4 bytes from this function.
The overall proposal saved 6% code on CoreMark and 7% on FreeRTOS.
Results from code size reduction
Zc saves about 12.5% on average across the benchmark suite. Further savings are achieved by a custom instruction for dictionary compression/instruction table. In combination these improvements can make RISC-V competitive with legacy processor architectures.
References
- [1] Opus audio codec
- [2] LC3 audio codec
- [3] CoreMark
- [4] Embench
- [5] FPMark
- [6] Benchmark results
- [7] C. Lefurgy, P. Bird, I.-C. Chen and T. Mudge, "Improving code density using compression techniques," Proceedings of 30th Annual International Symposium on Microarchitecture, Research Triangle Park, NC, USA, 1997, pp. 194-203
