In our first blog in this series, we looked at the high costs associated with memory safety failures. In the second post we saw that commonly used methods to ensure processor integrity were not adequate. This means that memory unsafety is a characteristic of many of today's systems. In this blog we look at some of the causes of memory unsafety.
What is memory unsafety?
In our previous blog post we looked at buffer bounds problems such as buffer overflows and over-reads. The root cause of these vulnerabilities is unsafe programming. Major software vendors consistently report memory unsafety problems. For example, the Chromium open-source browser project has stated that 69% of CVEs (Common Vulnerabilities and Exposures) reported relate to memory unsafety.
According to software resilience engineer Alex Gaynor's article:
If you have a very large (millions of lines of code) codebase, written in a memory-unsafe programming language (such as C or C++), you can expect at least 65% of your security vulnerabilities to be caused by memory unsafety.
He based this claim on data on operating systems including Android, iOS, macOS and Ubuntu as well as multiple web browsers.
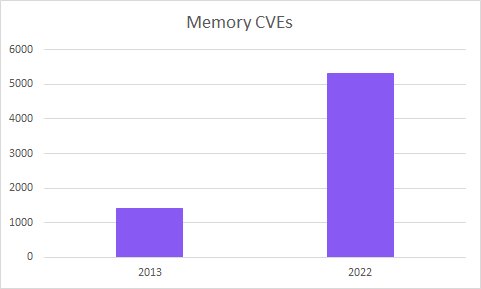
Not only are memory safety vulnerabilities a significant proportion of those reported for operating systems and browsers, but they are growing in number. There were x3.7 more memory-related CVEs in 2022 than in 2013.
Memory vulnerabilities are usually classified into two categories: spatial and temporal. Exceeding buffer bounds when reading or writing data are called spatial vulnerabilities. Memory locations can contain different data at different times during program execution. Temporal vulnerabilities relate to when say a program uses a certain memory location using a pointer, then later frees the memory and then tries to use the pointer again when it is no longer valid. Trying to use a so-called “dangling pointer” is referred to as a use-after-free bug and was a common problem for the Chromium project. Temporal vulnerabilities can result in unpredictable behavior as well as being exploitable by hackers. Dangling pointers can also lead to memory leaks.
Pointers and memory management
C and C++ languages
There is a huge body of code written in C and C++ with over 13 billion lines of code on GitHub alone. These languages offer tremendous control over memory but since memory management is manual there are great risks of making errors. The languages were developed when memory was very expensive and having manual control of memory allowed programmers to achieve better performance with available resources. In the case of C there were some missing features including arrays, strings, and writeable function parameters. These limitations have been overcome by using pointers.
Pointers
Pointers are variables that contain the address of another variable. By performing operations on the pointer, it is possible to operate on arrays or strings. However, pointers are used for very different purposes making reading C code challenging at times. When a variable is accessed in C it is copied into the call stack. However, if a variable is large such as a big array or string, if pointers are used it is only necessary to copy the pointer rather than the entire variable. This leads to better performance and efficiency.
Memory allocation
Allocating memory, for example, for a string requires the programmer to estimate the amount of memory required. Of course, if a longer string is required than allocated then it is possible to make a new memory allocation, and then copy the contents character by character to the new memory before freeing the old one. In practice programmers have often used guesswork to size their arrays and strings, have not coded bounds checks and have sometimes simply hoped for the best.
Pointers use generic integers and there are no automatic bounds checks with these languages, so it is easy to inadvertently create a buffer overflow or over-read. The same applies to temporal problems such as use-after-frees. This means that pointers are both powerful and dangerous.
Multi-threading
Multi-threading adds an extra complexity level and tends to exacerbate problems with memory unsafety. The use of multi-threading is becoming widespread due to the use of multi-core systems and the end of or slowing of semiconductor scaling. Bugs are possible due to slight differences in the timing of different threads running.
There are three main approaches to mitigating or avoiding memory unsafety:

In the next post we will look at both software methods to address memory safety as well as safe programming languages.
