In recent years, the rapid advancement and adoption of Artificial Intelligence (AI) on the edge has brought about a surge in development. As AI models like ChatGPT become more prevalent and accurate, the computational requirements for inference also escalate. This necessitates architectural innovations aimed at reducing both power consumption and latency.
The need for edge computing
As machine learning permeates various aspects of our daily lives, the amount of data processed by our devices is skyrocketing. To handle the heavy computational load, many devices leverage cloud computing to transmit and offload data to servers. However, this approach isn't without its drawbacks.
Transmitting data over the internet introduces latency, which can be problematic for real-time applications such as self-driving cars. Edge computing, where computation is performed locally, emerges as a solution to address these latency issues. However, it introduces new challenges, particularly in terms of performance and power efficiency.
Computing large volumes of data in battery-powered units poses significant challenges compared to servers with virtually limitless power supplies. Recent AI models, particularly large language models like ChatGPT, consist of billions of parameters that need to be shuttled between memory and processing units. This data movement creates a bottleneck for efficient AI inference. Transitioning towards a more data-centric architecture, such as Near Memory Computing (NMC), can mitigate these issues by moving data-intensive calculations closer to the source of the data, thereby reducing latency and power consumption.
Edge AI research at Lund University
A partnership between Lund University in Sweden and Codasip's University Program has yielded impressive results in the edge AI domain, showcasing the collaborative efforts between academia and industry in advancing processor design and embedded systems. Lund University's engagement with Codasip's resources, including the L31 3-stage RISC-V core and Codasip Studio for customization, coupled with guidance from Codasip experts, has enabled the development of innovative solutions in the field.
A team, headed by Prof. Joachim Rodrigues and Dr. Per Andersson, comprising several PhD students at Lund University embarked on a project to build a sophisticated system incorporating various architectural innovations, including Codasip's L31 core, their RTL DMA (Direct Memory Access), Codasip's interconnects, and their NMC integrated on L2 cache level. Their configurable NMC can realize various neural network models and is designed from scratch and is used for efficient and parallel inference of convolutional operations of CNNs.
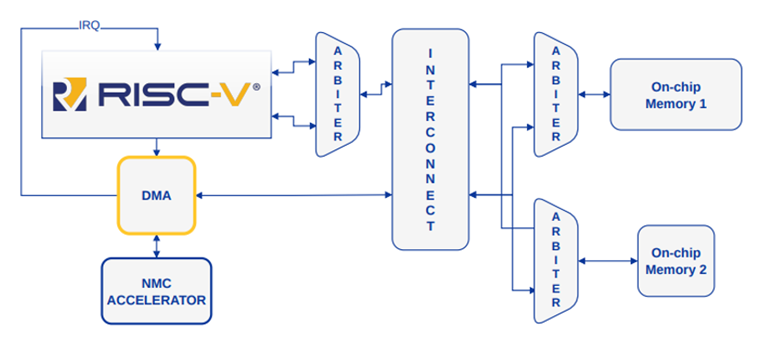
This comprehensive system architecture demonstrates the integration of cutting-edge technologies to address the problem of efficient AI-on-the-edge acceleration.
Custom instructions to increase performance
One notable achievement of the collaboration is the customization of the L31 RISC-V core with custom instructions tailored to the specific requirements of the system. These custom instructions enable direct interfacing with the DMA, streamlining data transfer operations and enhancing overall system performance. Additionally, the customization of the L31 core with MAC (Multiply-Accumulate) instructions facilitates the acceleration of fully-connected layers in convolutional neural networks (CNNs) as well, a critical aspect of deep learning inference and separated from convolutional operations that their accelerator is used for.
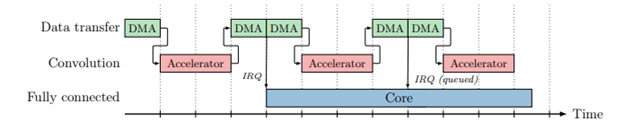
The final quantitative results can best be summed up by a quote from a master’s thesis, which was carried out by two of the current PhD students.
‘In conclusion, this thesis has demonstrated the possibilities of attaching NMC units to customized RISC-V cores. Through the integration of a custom DMA and specialized RISC-V instructions, the system achieved a performance increase of 11.7×, compared to the baseline scenario, with a reasonable impact on area. Additionally, the text size of the program was drastically reduced to 6.2% of the baseline scenario, indicating a potential for reduced memory area requirements’
Accelerated chips ready for tape out
We recently advanced the partnership further by taping out a new version of the accelerated SoC in an advanced CMOS node, with the chips expected to be available by late summer. This milestone underscores the practical realization of the collaborative efforts, bringing the developed system closer to real-world deployment. In the interim, the system is operational on an FPGA platform, with ongoing work focusing on developing a demo application for radar-based hand gesture recognition.
Overall, the partnership between Lund University and Codasip's University Program exemplifies the synergistic relationship between academia and industry in pushing the boundaries of processor design and embedded systems. Additionally, it showcases how Codasip’s RISC-V processors and Codasip Studio can be used for efficiently designing custom, application specific CPUs and systems. Through combined expertise and resources, the collaboration has yielded tangible outcomes, paving the way for future innovations and advancements in the field.
Lund University master’s thesis is publicly available online.
