Tariq Kurd, Distinguished Engineer and Lead IP Architect
RISC-V is a powerful instruction set that is constantly evolving. One of the recent evolutions relates to code size reduction. Last year, the RISC-V Zc extensions were ratified. The team at Codasip led this work, and as I have been closely involved, I would like to explain the possibilities of these extensions.
Reducing the code size of your core can have benefits you might not have considered:
Lower system cost
In small embedded systems, the processor’s size is less critical than the size of the Boot ROM and the external flash memory. So, what if you increase the processor size by 1-3% to add functionality for code size reduction? As a result, the code size can shrink by up to 20%. You can fit your software into much smaller ROMs and flash memory, reducing the total system cost despite a modest increase in processor size and power consumption.
Reduced power and boosted performance
Smaller code reduces the number of memory fetches, lowering latency and power consumption. It also enhances performance by minimizing time spent waiting on cache misses to be serviced, or waiting for Direct Memory Access (DMA) engines to fill Tightly Coupled Memories (TCMs) in processors without caches.
Let’s now look at 3 steps to shrinking your code size.
Step 1: Pick a RISC-V core that supports the Zc extensions
The Zc extensions are added on top of the RISC-V standard compressed instruction-set extension, named “C”. The C extension reduces static and dynamic code size by adding short 16-bit instruction encodings for common operations, allowing more code to fit in the instruction memory or cache.
The Zc extensions cover RISC-V implementations from high-end application cores to microcontrollers. They are particularly useful for small devices that use on-chip memory, or off-chip flash to store code, as opposed to the DDR or even HBM off-chip memory used in larger systems.
As part of the work in RISC-V International’s Code Size Reduction Working Group, we have used benchmarks to see how useful the Zc extensions really are. To get this data, we used test cases from Opus and LP3 audio codecs, CoreMark, Embench, FPMark, and Debian benchmarks. To eliminate compiler dependencies, we evaluated both GCC and LLVM. We assessed each group of Zc instructions along with a proposed custom instruction for dictionary compression. The full benchmark results are available online. The Zcmp extension for push/pop and the Zcmt extension for table jump provide the best size savings for small devices but aren’t suitable for high-end cores. The Zcb extension on the other hand is suitable for all cores. Let’s explore this extension a bit more.
The potential of Zcb
The Zcb extension is simple enough for all architectures and is included in the RVA23 application profile.
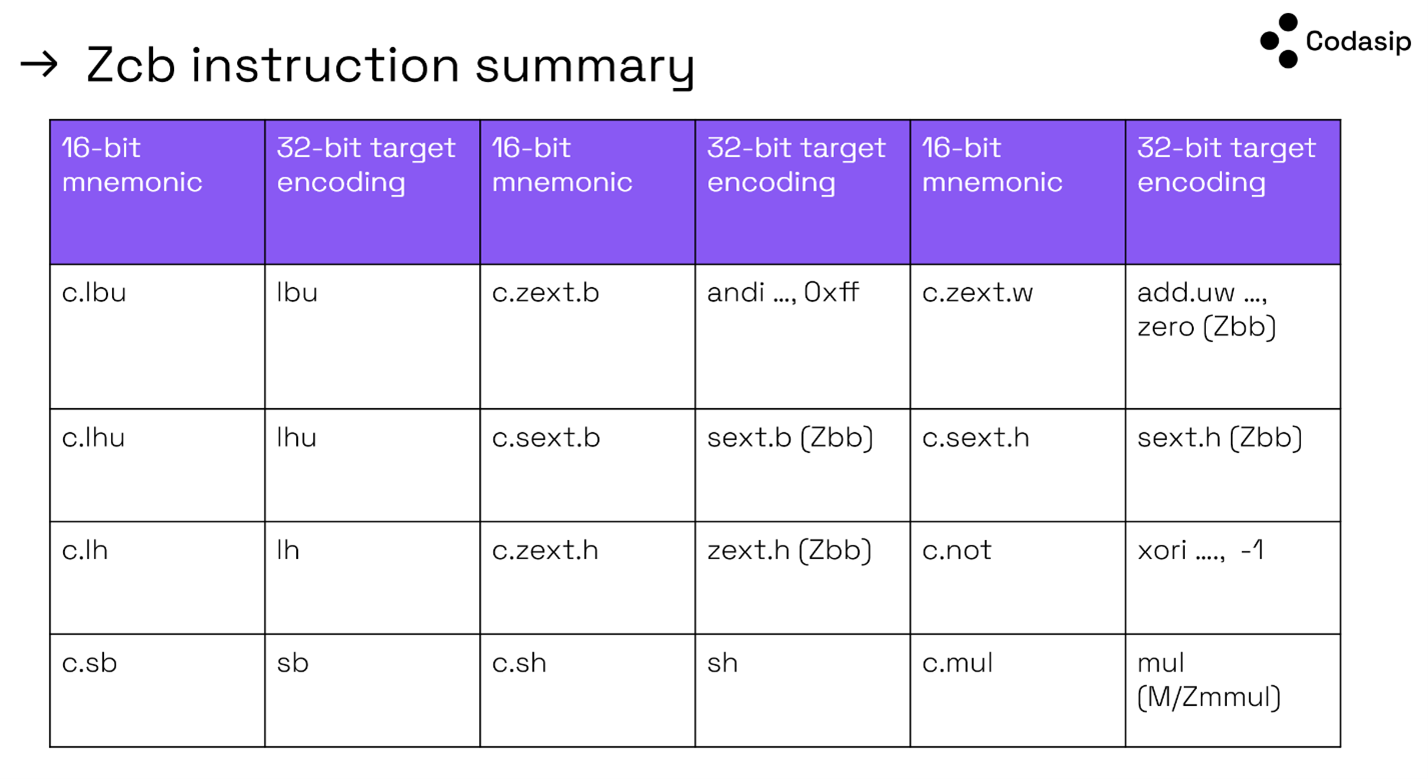
These instructions only allocate reserved encodings, typically saving 0.5-2% of code size, at the price of (up to) 12 lines in your decoder. For some Embench benchmarks, the improvement is even up to 5-6%.
The most straightforward way to get access to these size-downs is to pick a RISC-V core that supports the Zc extensions, like our low-power embedded core Codasip L110.
Step 2: Implement the instruction table as a custom extension
Dictionary compression is not new. This technique has been used for code size reduction in computer architectures since at least the 1990s and it is commonly used in compression algorithms. Basically, it replaces common patterns with a short index in a table or dictionary.
The method used for this benchmarking involves a table of micro-code routines in memory, with a 16-bit instruction calling an entry. Initially, each micro-code sequence is limited to a single 32-bit instruction.
This method allows a 16-bit encoding to expand to any 32-bit instruction, except for PC-relative ones, which are illegal. Let’s look at an example. In the Embench benchmark, there is a function called picojpeg. Because the 32-bit encoding for “lui a5,0x0” is used twice in this function, allocating the encoding into the instruction table replaces every usage with a 16-bit fetching instruction, saving 4 bytes in the process.
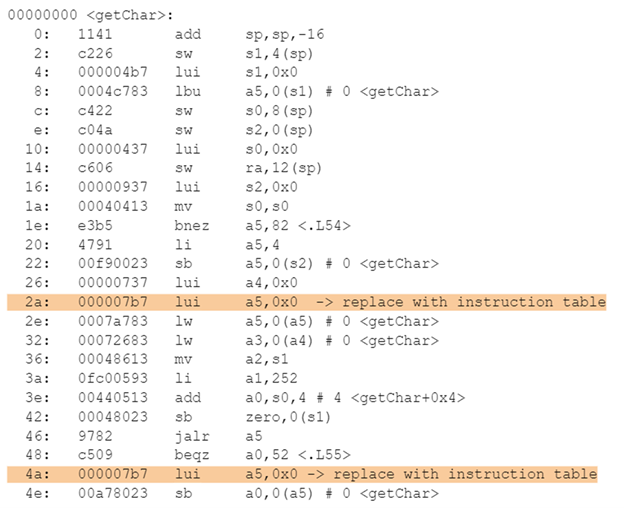
The Codasip team has added support for the CPU implementation of the instruction table as a custom extension. This means that Codasip Studio can generate a custom LLVM compiler that understands the custom instructions.
Step 3 (very easy step!): Enjoy the results
Our benchmark tests show that with Zc and the instruction table, a 21% code size reduction can be achieved. This is massive! Zc alone saves 12.5% on code size across the benchmark suite. This makes our implementation the market leader in code density in the RISC-V space, and it is highly competitive with legacy architectures.
If you are already a RISC-V developer, it’s time to shrink your code size, your costs, and your power consumption.
If you are yet to start your first RISC-V project, I hope this data has eased any potential concerns you have about the code size not being competitive. It is highly competitive. And, there is space available for more compressed encodings.
