How to Choose an Architecture for a Domain-Specific Processor
29 January, 2021
If you are going to create a domain-specific processor, one of the key activities is to choose an instruction set architecture (ISA) that matches your software needs. So where do you start? Some companies have created their instruction sets from scratch, but if you have such an ISA, a penalty may be the costs of porting software. Today, the RISC-V open ISA can provide you with an excellent starting point and a software ecosystem. Depending on what you need, there are several obvious starting points. In case of a 32-bit processor, if you start with RISC‑V, the base ISA (RV32I) is just 47 instructions. Using this base set is easier than creating proprietary instructions with similar functionality, as well as meaning that software is already available from the RISC-V ecosystem.
Starting point
Number of instructions
RV32I
47
RV32IMC
101
RV32GC
164
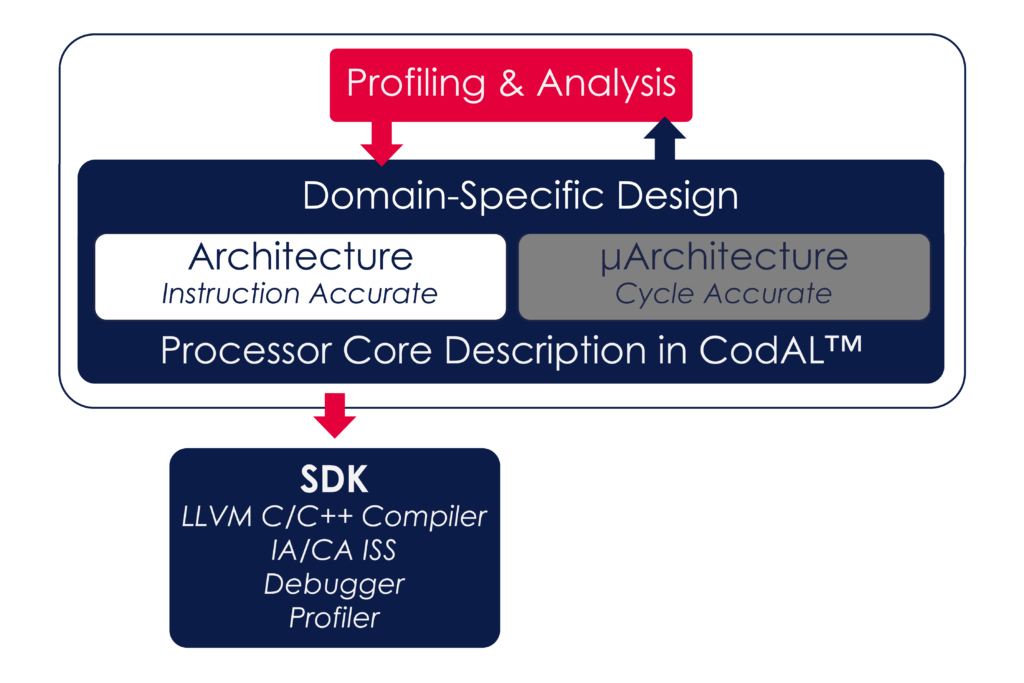
Many use cases require multiplication suggesting that [M] extensions would be useful, and it is sensible to take advantage of the 16-bit compressed [C] instructions for code density, so it is commonplace to use the RV32IMC set which amount to 101 instructions. Using RISC-V as a starting point will ensure that it is straightforward to use common software such as an RTOS or protocol stack. If you additionally require floating point computation, then the RV32GC (G=IMAFD) instructions may be appropriate, additionally including atomic [A], single-precision floating point [F], and double-precision floating point [D] extensions. Even RV32GC only has 164 instructions. The RISC-V ISA is designed in a modular way that allows processor designers to add not only any of the standard extensions, but also to create their own custom instructions while keeping full RISC-V-compliance. The standard extensions are a convenient option thanks to being readily available; however, some may substantially increase the instruction set complexity. For example, the complete set of packed SIMD extensions [P] adds 331 additional instructions. In many cases, sufficient gains for a particular application can be made with custom instructions with potentially a lower overhead in silicon area and power. Having chosen the starting point for your domain-specific processor, it is then necessary to work out what special instructions are needed to meet your computational requirements. This requires a careful analysis of the software that you need to run on your processor core. A profiling tool allows computational hotspots to be identified. Once such hotspots are known, a designer can create custom instructions to address them. Therefore, a designer can iterate by experimenting with adding or deleting instructions, then profiling the software again and assessing whether the changes have achieved their objectives. However, while this iterative process is logical, how would you actually do it in practice? You might be able to access an open-source instruction set simulator and toolchains such as GNU or LLVM, but modifying these by hand is something for toolchain specialists and is time-consuming. The alternative is to describe the instruction set using a processor description language. In Codasip Studio, an instruction accurate (IA) model of a processor can be created using the CodAL processor description language. An SDK including compiler, instruction set simulator (ISS), debugger, and profiler can be automatically generated from the IA description. By describing the ISA at a high level and automatically generating the SDK, it is possible to rapidly iterate experiments in extending the instruction set. In this way, it is possible to choose a well-optimized ISA for a domain-specific processor, sometimes known as an Application Specific Instruction Processor (ASIP). Generating the SDK automatically is not only faster, but less prone to errors than manual changes, meaning that the design process is cheaper and more predictable, avoiding unnecessary risk and roadmap disruptions.
Roddy Urquhart Senior Technical Marketing Director
 If you are going to create a domain-specific processor, one of the key activities is to choose an instruction set architecture (ISA) that matches your software needs. So where do you start? Some companies have created their instruction sets from scratch, but if you have such an ISA, a penalty may be the costs of porting software. Today, the RISC-V open ISA can provide you with an excellent starting point and a software ecosystem. Depending on what you need, there are several obvious starting points. In case of a 32-bit processor, if you start with RISC‑V, the base ISA (RV32I) is just 47 instructions. Using this base set is easier than creating proprietary instructions with similar functionality, as well as meaning that software is already available from the RISC-V ecosystem.
If you are going to create a domain-specific processor, one of the key activities is to choose an instruction set architecture (ISA) that matches your software needs. So where do you start? Some companies have created their instruction sets from scratch, but if you have such an ISA, a penalty may be the costs of porting software. Today, the RISC-V open ISA can provide you with an excellent starting point and a software ecosystem. Depending on what you need, there are several obvious starting points. In case of a 32-bit processor, if you start with RISC‑V, the base ISA (RV32I) is just 47 instructions. Using this base set is easier than creating proprietary instructions with similar functionality, as well as meaning that software is already available from the RISC-V ecosystem. The alternative is to describe the instruction set using a processor description language. In Codasip Studio, an instruction accurate (IA) model of a processor can be created using the CodAL processor description language. An SDK including compiler, instruction set simulator (ISS), debugger, and profiler can be automatically generated from the IA description. By describing the ISA at a high level and automatically generating the SDK, it is possible to rapidly iterate experiments in extending the instruction set. In this way, it is possible to choose a well-optimized ISA for a domain-specific processor, sometimes known as an Application Specific Instruction Processor (ASIP). Generating the SDK automatically is not only faster, but less prone to errors than manual changes, meaning that the design process is cheaper and more predictable, avoiding unnecessary risk and roadmap disruptions.
The alternative is to describe the instruction set using a processor description language. In Codasip Studio, an instruction accurate (IA) model of a processor can be created using the CodAL processor description language. An SDK including compiler, instruction set simulator (ISS), debugger, and profiler can be automatically generated from the IA description. By describing the ISA at a high level and automatically generating the SDK, it is possible to rapidly iterate experiments in extending the instruction set. In this way, it is possible to choose a well-optimized ISA for a domain-specific processor, sometimes known as an Application Specific Instruction Processor (ASIP). Generating the SDK automatically is not only faster, but less prone to errors than manual changes, meaning that the design process is cheaper and more predictable, avoiding unnecessary risk and roadmap disruptions.