Effectively hiding sensitive data with RISC-V Zk and custom instructions
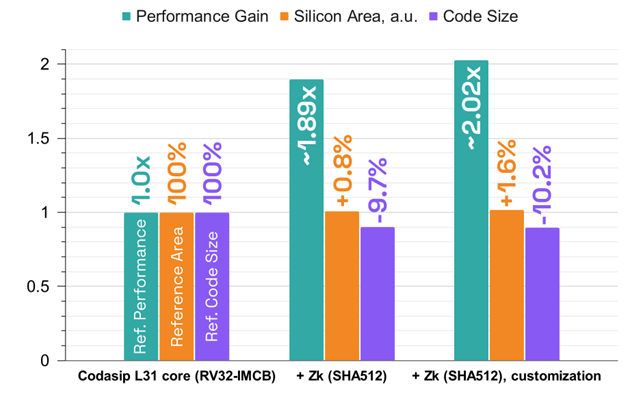
Cryptographic hash functions play a critical role in computer security providing a one-way transformation of sensitive data. Many information-security applications benefit from using hash functions, specifically digital signatures, message authentication codes, and other forms of authentication. The calculation of hash functions such as SHA512, SHA256, MD5 etc is a potential playground for Custom Compute. This […]
Customization? Yes! After tape-out? Yes!

Another RISC-V Summit is behind us. It was a very well-attended event with many exciting talks and companies highlighting their products at the exhibition. One of the main themes was, once again, customization. Many people and companies, including Meta in their keynote, insisted on the importance of customization and how this key aspect of the […]
Configurable LLDB for (not only) embedded RISC-V processors

At some point, software developers or processor developers need to check and debug their code. They can do this at different levels, for example looking at waves or parsing printouts, but the preference is to check code in an interactive session. The debugger facilitates the interactive session by accepting developers’ commands, executing them, and showing […]
Re-targetable LLVM C/C++ compiler for RISC-V

RISC-V is a modular instruction set architecture (ISA) with great customization capabilities that enable innovation and differentiation without fragmentation. On top of the baseline modules from ratified/standard ISA extensions, such as integer instructions or floating-point instructions, designers can add custom instructions: pure design freedom! And the reasons for adding instructions are many: better performance, smaller […]
It’s all about RISC-V code size
Here at Codasip we’re passionate about reducing the code size of our RISC-V cores for our customers, but why? Are we not making the core larger and more complex as we add instructions to improve the situation? In short the answer is yes we are, any instructions added to the processor increase the size, complexity, […]
No one-size-fits-all approach to RISC-V processor optimization

As the demand for high-performance processors continues to grow and semiconductor scaling laws continue to show their limits, the need for processor optimization is inevitable. As I explained in a previous blog, RISC-V is designed to enable this. However, there is no one-size-fits-all approach to processor optimization. As each workload and each application will have […]
RISC-V customization, HW/SW co-optimization, and custom compute
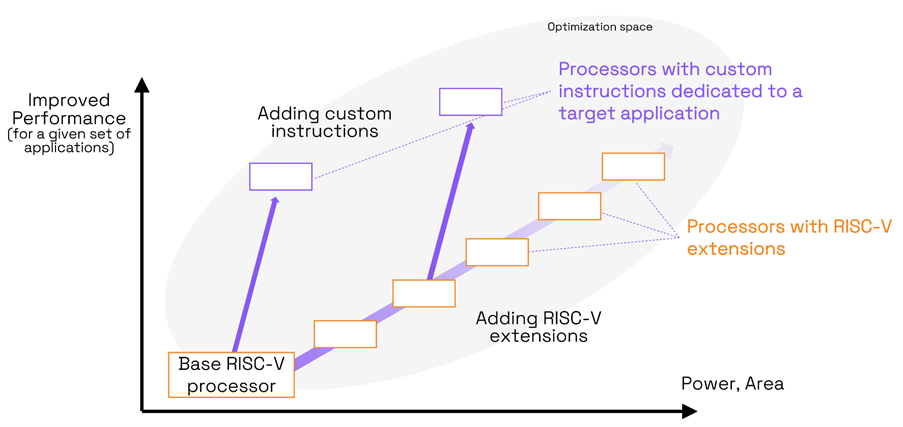
Do we still need to introduce and define RISC-V? You know, the open-source instruction set architecture (ISA) that is gaining popularity thanks to its flexibility, scalability, and modularity. Okay, we just did, just to be sure we are all on the same page. One of the key benefits and the main “raison d’être” of RISC-V […]
Codasip Studio 9.2.0: what’s new?

Codasip Studio in its 9.2.0 release is now available. This new version of our unique processor design automation toolset comes with a series of new features that both expand and optimize its applications. The new features supported in Codasip Studio 9.2.0 include: Macro Processor. Arrays in CodAL. uRISC-V 2.0. Pipeline definition in modules. Simulator Save state and […]
What is CodAL?

CodAL is central to developing a processor core using Codasip Studio. It is a C-based language developed from the outset to describe all aspects of a processor including both the instruction set architecture (ISA) and microarchitecture.