In our first episode from last week we focused on best practices when setting up formal verification on a component. Our setup is now ready with protocol checkers to avoid unrealistic scenarios (which also helped find a new bug), and with basic abstractions to improve performances. It’s now time to tackle our real task: reproducing a deadlock bug found using simulation. Let’s dive deep into it.
Reproducing the deadlock bug
To ensure a design is deadlock free, one approach consists in verifying that it is “always eventually” able to respond to a request. The wording is important. Regardless of the current state and the number of cycles we must wait, in the future the design must respond.
This translates very nicely using a type of SystemVerilog Assertion called “liveness properties”:
can_respond: assert property(s_eventually design_can_respond);For the cache we are verifying, we define this property on the Worker ports:
resp_ev: assert(s_eventually W_HREADY);Because the deadlock bug also appears as W_HREADY remains LOW forever on the Worker interface, we believe this assertion is the simplest and most generic one to check.
Note: There is a lot of theory behind the concept of liveness properties, compared to safety properties. This and the differences between formal algorithms to verify liveness assertions are not needed here and out of the scope of this blog.
Hello failures
However, by proving the above assertion, we quickly got failures. Then, we used the method and tool support as detailed here.
The deadlock we found was “escapable”. In other words, the abstraction on the invalidation counter (see episode 1) allows it to never reach the end value. In this scenario the cache is “not eventually” responding because it is staying in the invalidation loop forever. It is an escapable deadlock because there exists an escape event (the counter reaching its end value and the invalidation stopping).
This is a false failure that we discarded adding a “fairness constraint”: a liveness property used as a constraint.
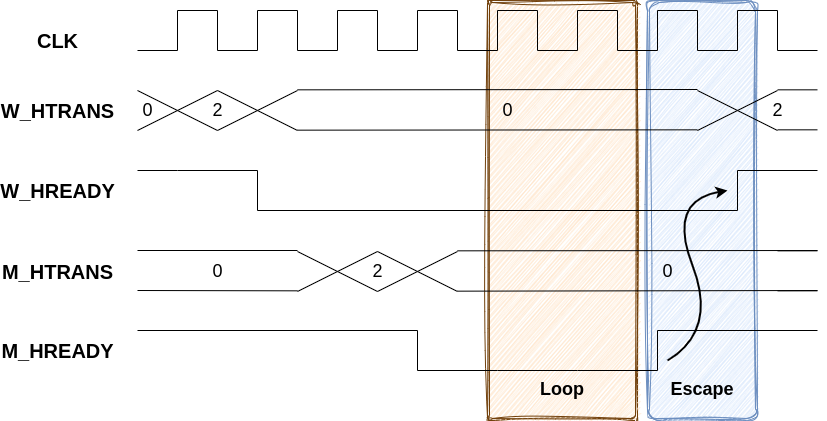
fair_maint: assume property(s_eventually maintenance_module.is_last_index);Similarly, M_HREADY on the Manager interface must be constrained to “always eventually” be HIGH. Otherwise the cache may stay in a state waiting for a response forever. This is visible on the following waveform.
In the Loop zone, W_HREADY on the Worker port may remain LOW forever if M_HREADY on the Manager port also remains LOW while a request is in flight. This Loop zone can be infinitely large, however the Escape zone shows that, if the environment eventually raises M_HREADY on the Manager port, then it unlocks the state and the same signal on the Worker port will also rise. This is an “escape event”.
From one failure type to another
After having fixed these false failures, we got another failure of the resp_ev assertion.
The result was more interesting: it was shown as an “unescapable deadlock”. It means that we did not have to try to identify other missing fairness constraints. There is one state where, regardless of what happens after, the design never responds.
The formal tool shows a waveform ending with an infinite loop, here in the Loop zone. This zone always extends to infinity on the right because there does not exist any escape event.
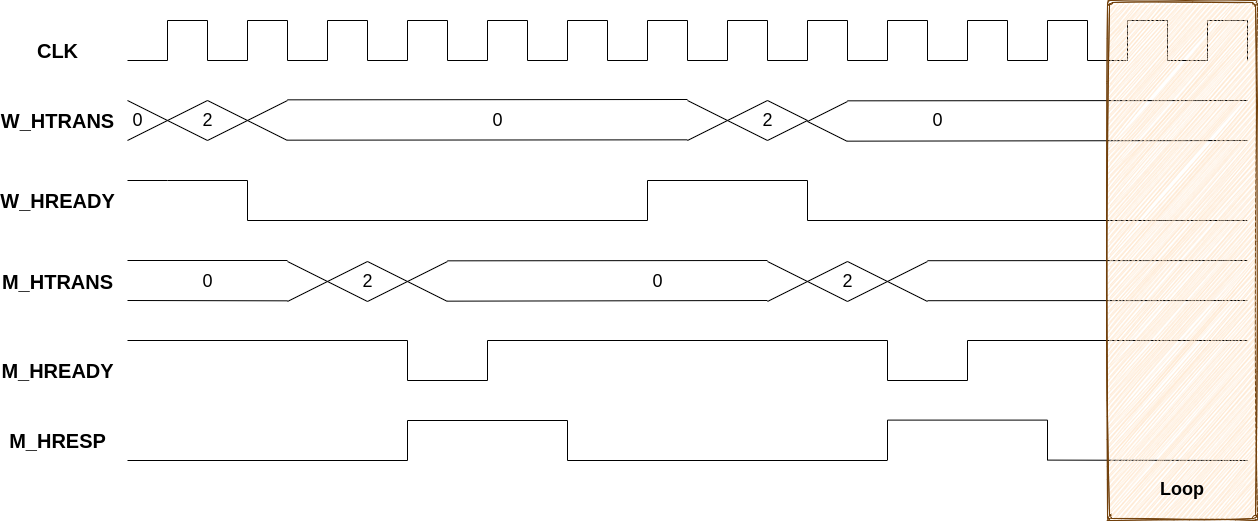
This is when designers confirmed “This is the bug!”. In less than a week, starting from scratch, we reproduced the bug. How cool.
Validating the RTL fix
We already had an RTL fix so it was quick to try it… and figure out it was not complete! We still got an unescapable deadlock. After a few iterations, things improved and we did not get any such failure anymore… but no proof either.
Increasing the time limit allowed us to get a full proof for the resp_ev assertion on the iCache bus (see episode 1). On the dCache bus we analyzed the bottleneck and found out it was caused by the ability to mix standard cache requests with requests to CSU dynamically changing the cache configuration. This makes the state space very large. Constraining the environment to avoid this made the proof converge.
Using over-constraints
During the debug iterations, we used over-constraints to reduce the exploration. This:
- Drastically reduces the time needed to get a counter-example or proof.
- Helps debugging failures because generated scenarios are simpler.
Of course, these over-constraints must be removed for the final runs.
It is important to allow over-constraining in an easy way in a formal setup. To be safe, it is best practice to forbid directly writing constraints (that is, assume properties) in the formal testbench. The risk of leaving some enabled at the end is too high. Instead, all properties must be written as assertions, and some can be switched to constraints with an explicit run option. This is something our formal framework allows us to do.
Other deadlock detection techniques
We’ve seen above how an FV tool can distinguish escapable and unescapable deadlocks. However, not all tools propose such a feature and here is a technique to mimic it:
- Write a liveness assertion A, in the form s_eventually expr
- Prove A with your tool. If it is proven, then you’re done: there is no deadlock.
- If you get a counter-example, you have a trace T ending with an infinite loop preventing it from getting expr true again.
- Run a proof of the witness of A, WA, using T to initialize the design, instead of the normal reset sequence. The formal analysis will start from the looping state.
- If the result of this proof is that WA is unreachable, it means T shows an unescapable deadlock.
- If WA is covered, it means T is an escapable deadlock and the trace of WA shows the escape event.
Proving liveness assertions is computationally more difficult than proving safety assertions. Therefore, it is sometimes preferable to verify deadlocks with a different approach.
Using bounded assertions
One approach consists in replacing a liveness assertion with a bounded one.
Instead of writing s_eventually expr, you can write !expr [*N] |=> expr. It means that expr is not expected to be false for longer than N cycles. This kind of property is very common in simulation testbenches. The difficulty is to set N large enough, but not too large! If N is set to hundreds or thousands of cycles, it is very unlikely that FV will get a result. If N is set small, there may exist events which make it being too small, and you will get false failures. The difficulty is thus similar to finding the fairness constraints to discard all escapable deadlocks when verifying the liveness assertion.
Using progress counters
Another approach is based on progress counters.
You must define a counter which increments each time something happens in the design, making it closer to a transaction completion for example. Then, a safety assertion can check that, if progress must be made, then, it is made. Taking the cache as an example, we can define the progress counter to increment when a request is made on one Manager port. It can also increment when parts of a burst are sent,… But in general, defining all the events which must increment the counter is difficult.
Further deadlock verification
After reproducing the targeted bug and validating the proposed RTL fixes, we wanted to go further.
We understood the bug was present only when using a “write-through” cache configuration. So the above work was done with a constraint to enable only this configuration. Of course, we wanted to ensure it was not present in the “write-back” configuration so we repeated the above process, lifting this constraint.
Then, we wanted to verify the absence of other deadlocks. These would not be visible on HREADY but on internal Finite State Machines (FSMs) in the design. Indeed a deadlock may appear as an FSM is blocked in a specific state forever, though HREADY is not blocked as LOW.
For this we identified the main FSMs in the design and generated liveness assertions checking that all states can be reached, eventually. For example:
fsm_dcache_miss: assert(s_eventually dcache.fsm_state == MISS);Hello failures – again
We quickly got many failures, all as escapable deadlocks.
For example, if the Worker port receives a continuous stream of requests to the same address. The first request may miss or hit. But the following ones will hit. And if the stream of requests is “dense enough” then there will be no wait cycles between each hit, so the FSM state is always HIT and cannot reach any other state, including MISS. That’s why the above assertion fails.
Fortunately, the tool indicates this failure is for an escapable deadlock. The escape is to make some space in the request stream, or to change addresses. To mask this scenario we need to add fairness constraints. But they seem to be very over-constraining, and reducing the verification scope a lot.
We finally decided to not do that. Instead, we let the tool run for a few days (a very long time for formal!) with different configurations. It reported many escapable deadlocks that we ignored. But no unescapable deadlock was found, raising our confidence even if not getting full proofs.
Recap
In this episode, we’ve looked into formal best practices for verifying a deadlock. Here are 3 key takeaways.

We reproduced the bug, validated the RTL fix, and greatly improved our confidence that no other real deadlock exists ahead of schedule. Of course we did not stop here. We are bug hunters. In the next episode, I will tell you how we verified other aspects of the design, including high-level properties.
