In previous blog posts we have considered the damage, costs and underlying causes of memory unsafety. Having looked at conventional approaches to protecting processor systems we concluded that standard approaches such as MPUs, MMUs and privilege modes while having some value are limited in effectiveness.
We also noted that while languages like C/C++ give tremendous control to programmers there is also a lot of room for errors because of the use of pointers. Pointers are variables containing memory addresses.
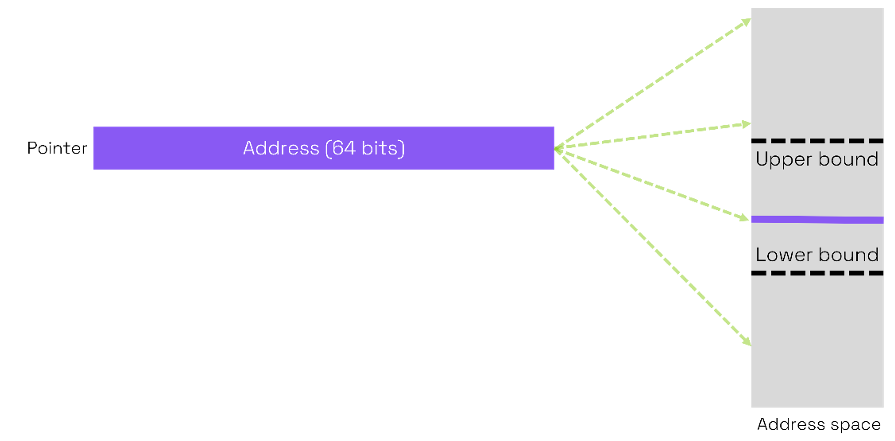
When a buffer is defined, the pointer has no information on the lower and upper bounds of the buffer. Therefore, it is possible to use the pointer to read or write within the bounds of the buffer, just outside the buffer or nowhere near the buffer. There are no built-in limitations to how pointers are used, so the programmer is free to compute their values as he pleases. This is an underlying cause of memory unsafety as programming errors are always possible and resulting illegal memory accesses are undetected.
With a huge body of existing code in these memory unsafe languages it is not economic to rewrite all the code in a memory safe language such as Rust. Software mitigations have been implemented but suffer from either limited coarse-grained statistical protection, in the case of stack canaries, or a heavy cost in resources with fine-grained approaches such as Firebloom.
This blog post looks into the alternative of fine-grained memory protection in hardware.
Is memory protection better in hardware after all?
Earlier we saw that coarse-grained memory protection such as MPUs and MMUs were limited in effectiveness and specifically were unable to deal with buffer bound vulnerabilities. These approaches were all coarse-grained. In the last decade multiple fine-grained memory approaches have emerged Including:
- Memory tagging
- Capability architectures
Both of these approaches use metadata to provide better ways to point to memory.
What is memory tagging?
One way to introduce finer granularity Is to extend pointers and memory with tags. Arm's Memory Tag Extension (MTE) operates with a lock and key mechanism. Four bits of metadata are added to each 16 bytes of physical memory together called a Tag Granule. The four bits act as the lock to the memory. A pointer also has 4 bits of meta data which is used as the key. A pointer may access a memory location if the pointer's key matches the lock tag for that location.
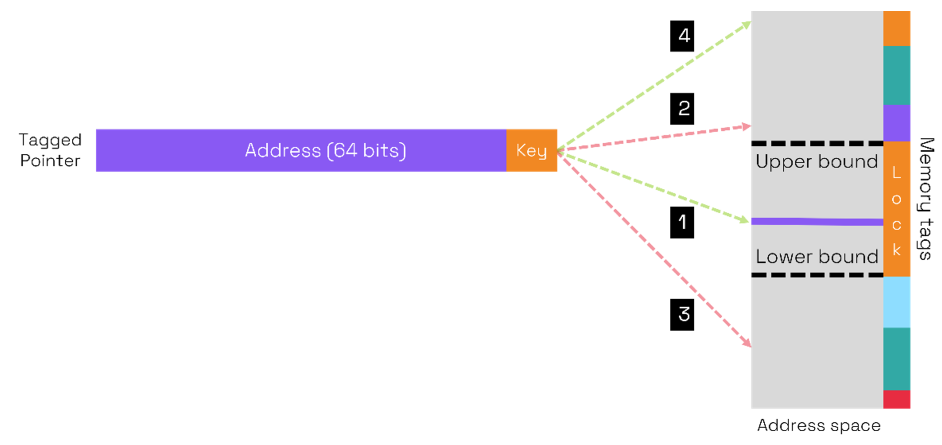
In the diagram above, we represent the content of memory tags by colors for example, the pointer key is orange. Consider 4 cases:
- The pointer address is within the buffer bounds and the key matches the lock (both orange) so access is allowed.
- The pointer address Is beyond the upper bound (as in overflow or over-read) and the memory tag is purple, the key tag does not match the lock, so access Is prevented.
- Similarly in this case the key does not match the green lock, so access is prevented.
- A limitation of the tags is that 16 values are possible and there may be more than 16 different regions of memory tagged. Thus, in this case if the pointer address matches a different region of memory with an orange lock the memory access will be allowed even although it has nothing to do with the intended buffer.
Memory tagging reduces the likelihood of buffer overflows and over-reads compared with classic MPUs and MMUs. However, it is a statistical rather than deterministic approach. This means that not all memory vulnerabilities will be covered. With only 16 possible values for a lock, a careful hacker can work on guessing the correct one.
MTE comes with some costs to hardware including an overhead in tag memory, and microarchitectural changes.
What are capability architectures?
Capability architectures take the use of metadata to a higher level by explicitly using the upper and lower bounds of buffers. In addition, there is a one-bit tag which indicates the validity of the capability. A capability can be regarded as a "smart pointer".
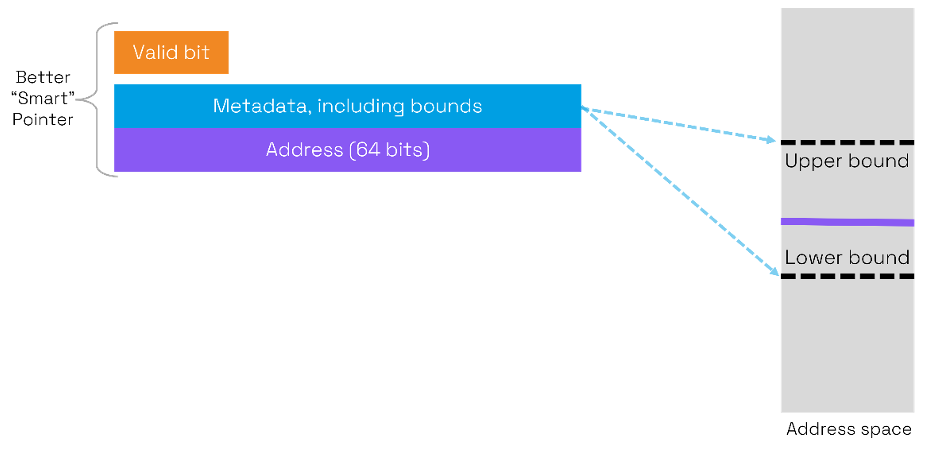
With the bounds of the buffer explicitly included in the metadata, Capabilities can be used to deterministically check for buffer bound violations.
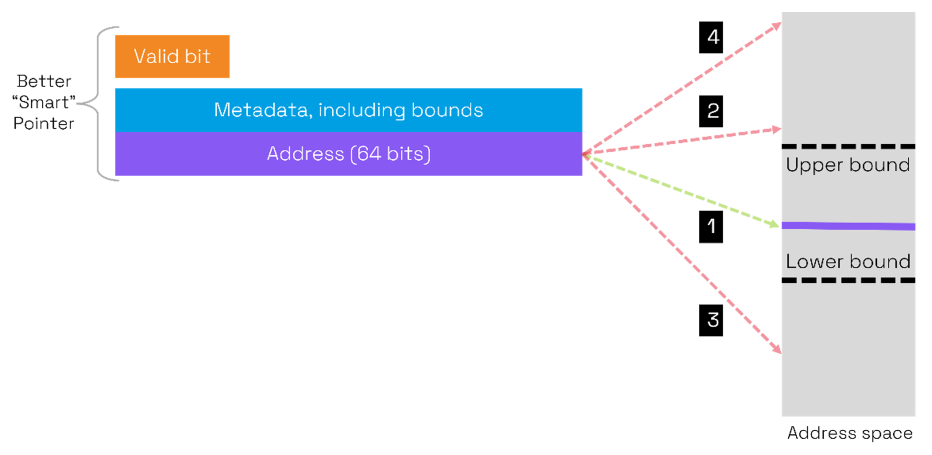
Returning to the four cases mentioned with memory tagging:
- The address lies within the bounds described in the metadata, so access is allowed.
- If the address goes outside the upper bound (buffer overflow or over-read) the address is not within the bounds defined in the metadata so access is prevented.
- In this case, the address points to an upper region of memory outside the intended buffer and access is prevented.
- In this case, the address points to a lower region of memory outside the intended buffer and access is prevented.
Capability-based memory access comprehensively prevents buffer overflows and over-reads and thus protects against many memory-related vulnerabilities.
What is CHERI?
The best-known example of using capabilities to deal with memory safety is the University of Cambridge's Capability Hardware Enhanced RISC Instructions (CHERI). This project has had the twofold aim of delivering fine-grained memory protection and scalable compartmentalization. It contains both hardware and software elements.
The CHERI concept is ISA-independent, and the University of Cambridge has created experimental versions for MIPS, Arm v8-A and for RISC-V. CHERI requires the use of additional instructions to handle capabilities as well as additional microarchitectural features. Adding CHERI to an existing processor architecture is a classic example of Custom Compute and is a key reason for Codasip adopting it in its processor cores.
Summary
In this series of blog posts, we have considered different approaches to improving memory safety through bounds protection. These are summarized in the table below.
| Method | HW or SW | Statistical or deterministic | Coarse- or fine-grained | Effectiveness of bounds protection |
| MPU | HW | Deterministic | Coarse-grained | Very limited |
| MMU | HW | Deterministic | Coarse-grained | Very limited |
| Stack canary | SW | Statistical | Coarse-grained | Limited |
| Firebloom | SW | Deterministic | Fine-grained | Exhaustive |
| Memory tags/MTE | HW | Statistical | Fine-grained | Moderate |
| Capability/CHERI | HW | Deterministic | Fine-grained | Exhaustive |
The most effective methods are deterministic and fine-grained as they can provide exhaustive bounds-checking. However, software approaches are computationally resource-heavy and not deployable in a scalable manner. CHERI with its hardware-supported capabilities provides an effective and cost-efficient way of protecting memory bounds.
