Many common vulnerabilities are related to software failing to respect the bounds of buffers. There are two main classes of buffer bound vulnerability – buffer overflow and buffer over-read. Both of these can lead to deviations in the execution flow or the malicious extraction of important data or code injection.
What are buffer overflows?
Buffers are used in many electronic systems - especially those in communication or streaming data. Buffer overflows occur when a process attempts to write data outside the bounds of the buffer. The result is that data is written into an area used for some other purpose resulting in the corruption of that memory. The damage varies depending on how the adjacent memory is being used.
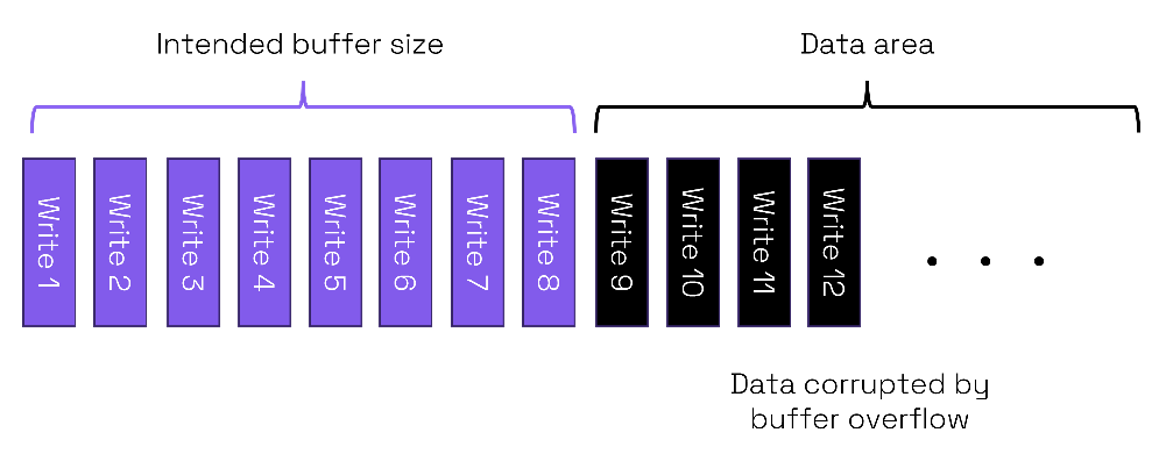
In the simplified example above a buffer is intended to have size 8 and is adjacent to a data area. If the buffer overflows to a data area, then it is likely that any program using that data may behave in an anomalous way or perhaps even crash.
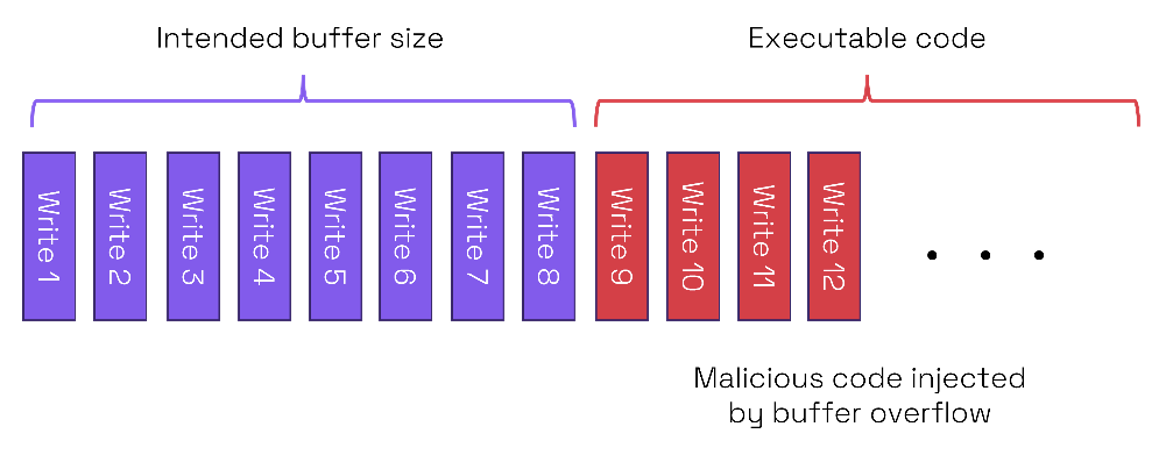
If the overflow is to an area containing executable code, then the vulnerability could allow a code injection attack. In the example above if the area of memory next to the buffer is used for executable code, then the buffer overflow can be used to write malware into the executable code area.
A specific type of attack known as “stack smashing” deliberately causes a stack overflow. Overflows of buffers on a stack can be exploited to overwrite local variables, return addresses and function pointers. Such overwriting can be used to point to malware rather than trusted code. Other attacks aim to corrupt the heap by using buffer overflows to overwrite data structures such as linked list pointers.
What are buffer over-reads?
The converse of a buffer overflow is a buffer over-read. In this case a program requests data from outside the buffer. Because the data that is read from outside the buffer has nothing to do with the program, it could potentially cause a program to crash or behave strangely. Worse still, it is another mechanism for breaching security.

In the example above we again have an intended buffer size of 8 but it is adjacent to data memory containing confidential information. If the program reads beyond the bounds of the buffer, it will start accessing unrelated confidential data.
Buffer over-reads have caused real world cyber-attacks with a well-known example being the Heartbleed vulnerability in OpenSSL. Examples of damage from Heartbleed include:
- Compromising 4.5 million patient records at the Community Health Systems hospital chain.
- Many web-based accounts compromised and needing new passwords.
- A hacker stealing 900 social security numbers from the Canadian Revenue Agency in a short period.
eWeek estimated that the total cost to industry to recover was $500M+. The vulnerability was made public in early April 2014 and a fixed version of OpenSSL was released the same day. However, in January 2017 180,000 connected devices were still vulnerable almost three years later! Even today there may be enterprise systems which are not correctly patched according to a blog by TuxCare. They say that there can be uncertainty over which libraries have been patched and inconsistent patching. If just one library is not correctly patched, then an organization is vulnerable.
What is Heartbleed?
The Transport Layer Security (TLS) and Datagram Transport Layer Security (DTLS) protocols are respectively cryptographic, and communications protocols widely used on the web, voice-over-IP and instant messaging. The Heartbeat Extension was proposed as a way of keeping open secure communications links without the need to renegotiate them.
In OpenSSL, a Heartbeat request from a client to a server would include a text payload and an integer giving the payload length. With a valid connection, the server should return the requested payload text to the client.
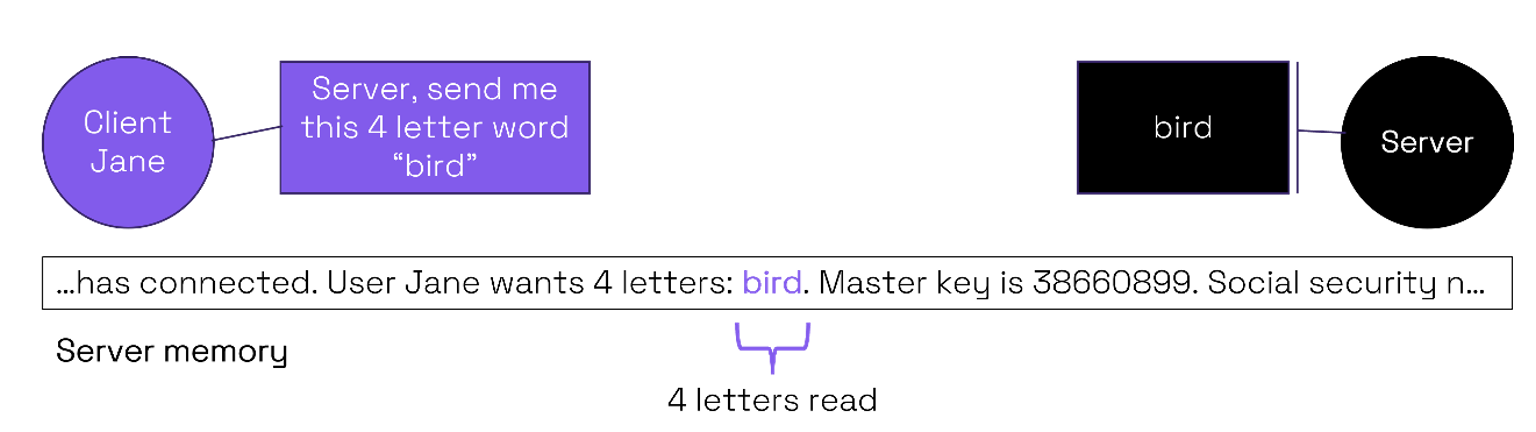
With the expected usage the size of the word (4 letters) requested by the client Jane would match that of the payload (“bird”). On the server side the 4-letter payload is read from the buffer and returned to the client.
However, with the vulnerable version of OpenSSL – Heartbleed - it was possible to request a payload length different to the actual size of the payload.

Therefore, a malicious request from the client could result in an over-read of the buffer. In the simplified example 100 letters are requested by Client Jane although the buffer is only 4 letters. This results in 96 letters of potentially secret information being over-read and transmitted to the client. This explains why confidential records were stolen from servers with this OpenSSL vulnerability.
The Heartbleed vulnerability was not only on the server side. The same buffer over-read technique could be used by malicious servers to access secret client data.
All because of unsafe programming
Buffer overflow and buffer over-read vulnerabilities have happened due to the absence of checking the bounds of the buffer.
In the buffer overflow cases, if the bounds of the buffer were checked before writing data, then it would not be possible to corrupt data or to inject malicious code in the way described.
Similarly, over-reading would not be possible if the buffer addresses were within the intended bounds. For example, the Heartbleed vulnerability would not have happened had the Heartbeat implementation checked the specified payload size against the actual payload.
Programming buffer accesses without checking the bounds is an unsafe programming practice. Unfortunately, widely used languages including C, C++ and assembly do not enforce bounds checking. These languages provide tremendous control over memory to the programmer, but this freedom can cause unsafe memory access.
In our next blog post, let’s dive deeper into unsafe programming. Stay tuned.
