As discussed in an another blog post by Mike Eftimakis, there are limitations to traditional design methods that use “off-the-shelf" processor cores. Traditionally, software engineers try to fit their code to the constraints of the chosen processor hardware. The alternative is to co-optimize the hardware and software together to create a custom compute solution. You could even think of it as being ‘software-defined hardware’.
To realize this vision a challenge is the shortage of processor design skills in the industry. This blog explores the industry’s skills trend and how the mismatch between available skills and demand can be solved.
The custom compute opportunity
The designers of systems are increasingly looking to differentiate their products through their silicon by adding their own “secret sauce”. Apple in the computer space and Tesla in the automotive space have demonstrated that their own SoCs directly add value to their end products and market valuations. This reverses a few decades of processor core consolidation into an ever-narrower range of processor IP products and suppliers.
In the same timeframe, semiconductor scaling has dramatically slowed down and moving to new finer technology nodes has become prohibitively expensive for many applications. A direct result is that more and more companies are wanting to create varied, specialized processing units where the design is matched to their computational workload.
A major barrier to this specialization is the finite number of processor design skills available.
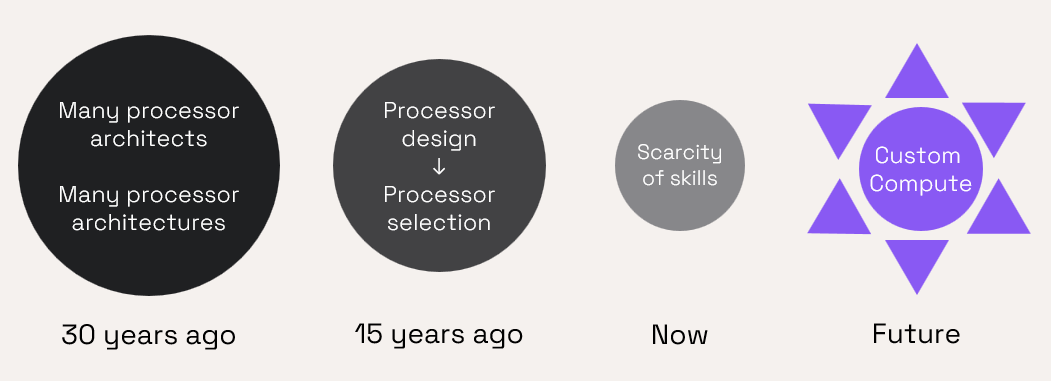
Thirty years ago, there were many processor architectures – even in microprocessors there was a choice between x86,MIPS, SPARC, Z80, and PowerPC. In the microcontroller area, many IDMs had their own architectures. This meant that many processor designers were required to support the wide range of architectures available.
By 15 years ago there had been some consolidation with x86 dominating the microprocessor market and Arm dominating the growing mobile phones application processor market. As proprietary architectures faded most of the slack was taken up by Arm embedded cores. The result was less processor development work and many design teams moving from processor design to processor selection from a few IP suppliers.
The market for processor design engineers continued to shrink and this led to less academic interest and less university graduates with processor design knowledge.
Today there is a scarcity of processor design skills just as the demand for custom compute is emerging in many applications. How can this mismatch be solved?
Revive processor design in universities
For the medium term, it is important to increase the number of students who learn processor design. Codasip is committed to helping educational institutions expand their courses through our University program. This aims to educate the new generation of processor designers by providing access to processor design automation and course materials.
However, there are shorter-term ways of addressing the skills scarcity.
Design automation
For most of the last 30 years, processor hardware design has been dominated by RTL-based design methods with a standard EDA flow to verify the RTL code. The corresponding development of a software toolchain has usually been independent of the RTL design. Typically, an open-source toolchain such as GNU or LLVM would be used as the starting point. To ensure that both HW and SW paths were compatible there would be strict adherence to the chosen ISA. Even companies with strong microarchitectural skills would rarely develop their own ISA but might purchase an expensive architectural license from an IP vendor.
Unlike other digital blocks on an SoC, the processor has to take account of both software and hardware worlds. Developing HW and SW in isolation from each other is inefficient and does not allow tradeoffs to be well analyzed.
Processor design automation tools, such as Codasip Studio , have existed for some years. They use an architectural language, like CodAL , to describe the processor. The tools automatically generate both the hardware design and software toolchain from the same description. This approach allows architectural tradeoffs to be rapidly made and to ensure that hardware and software worlds are consistent.

Despite the availability of processor design automation, only a few teams had the correct combination of skills to create a new instruction set and microarchitecture. Application-specific instruction set processors (ASIP) with custom architectures were rarely designed due to the difficulty of combining architecture, RTL design, software toolchain and application software knowledge in one team.
RISC-V has changed the game. RISC-V has a simple base instruction set which takes care of a key part of developing an instruction set. The ISA is modular meaning that it can be tuned to the needs of a particular software workload by combining RISC-V optional standard extensions and custom instructions. This big flexibility is not matched by commercial proprietary architectures even extensible ones.
Incremental design
Another approach to the skills shortage is simply to avoid designing the whole core. If a RISC-V core is available in an architectural language, then it is possible to create a derivative design by simply designing the “delta”, from a baseline design. Firstly, it is possible to create custom instructions and secondly there can be microarchitectural enhancements.
RISC-V custom instructions can significantly improve the performance of a resource-constrained core in applications such as cryptography, neural networks and DSP. To create custom instructions, it is necessary to profile the software to identify computational bottlenecks and then to devise new custom instructions to address them.
Microarchitectural features can be added to improve the interface between incoming data and a processor core. For example, the Codasip applications team created a FIFO register chain and weight storage to enable the efficient implementation of a convolutional neural network (CNN) on a small L31 embedded core.
Adding some features to an existing core requires less skills than designing a brand new core. For example, embedded software developers are familiar with profiling and analyzing computational bottlenecks. Such developers can devise new instructions and to re-profile their SW workload. Hardware designers would be able to add incremental architectural features to an existing core design.
