Hi again, friends. Here we are. This is the last episode of our series on formal verification best practices. As the last step, let’s discuss signing off with formal verification, and wrap up. After our efforts using formal verification to verify our cache controller, we went beyond expectations. We reproduced and qualified the design fix for a known deadlock. We also verified data integrity and protocol compliance. However, we did all that without looking at the cache microarchitecture, therefore we don't have any embedded assertions.
Now the questions are: Are we done? Is this verification sufficient? With a few tricks we were able to get proof convergences, but are we observing all possible bugs? We can typically answer these by looking at formal coverage.
Note: if you’ve missed an episode or would like a refresher, check the links at the bottom of this page.
A taxonomy of formal coverages
Before collecting coverage we first need to define what we want to observe. Similar to code coverage in simulation, formal coverage can observe branches, statements, conditions, and expressions. It can also observe the cover points defined for functional coverage. All these are called "coverage items" (CI). In practice, we find it useful and enough to select branches, statements, and cover points if present.
There are actually different types of formal coverage. Let's examine them.
Reachability coverage
This one needs a formal analysis to determine whether each CI can be covered or not. This is very similar to measuring code coverage in simulation. It is completely independent of the assertions.
Static coverage
Static coverage is also called ConeOfInfluence (COI) coverage. This one does not need to run any formal analysis. Each CI is flagged as covered if it is present in the COI of at least one assertion.
Observability coverage
This one needs a formal analysis of the assertions. During that analysis, the proof engines report the CI which have been instrumental to conclude the proof.
Note that:
- Bounded proofs also contribute to this coverage.
- Mutation coverage is a very similar metric, but using a different technique. It does not scale well with formal.
Bound coverage
In case some assertions are not exhaustively proven, the proof bound is compared with the bounds (obtained by reachability coverage) of the CIs in its COI.
Now let’s look at the first three types of coverage in more detail.
Who is good at what?
The following table shows which issues each coverage is able to detect, with the primary ones indicated between brackets.
| Reachability | Static | Observability | |
| Dead-code | Y (primary) | Y | Y |
| Over-constraints | Y (primary) | N | Y |
| Badly written assertions | N | Y | Y (primary) |
| Need for abstractions | Y (primary) | N | Y |
| Need for assertions | N | Y (primary) | Y (primary) |
| More proof effort (time, grid) | Y (primary) | N | Y (primary) |
The reachability coverage is a good indication of how good your formal tool is able to analyze the design, given a time / CPU budget. If that is not sufficient, it means new abstractions may be added. This coverage also tells you about pieces of code which are not covered because they are dead (a design issue), or because constraints prevent that (a formal testbench issue).
Static coverage can give you a very quick view of which parts of the design are definitely not checked by any assertion. If these parts have to be verified with formal, then you need to add new assertions. Because of the nature of the designs, this coverage is often very high, very easily. But that must not keep you satisfied!
Observability coverage, also called "proof coverage", is probably the most important one. It is always a subset of static coverage. Indeed, some logic may be in the COI of a specific assertion, but actually not in the observability coverage of this assertion. That means looking at the static coverage without looking at the observability one is an over-optimism and a huge mistake!
For example, consider the logic in the blue bubble below is huge and complex. An assertion is written as
o_always_high: assert property(o);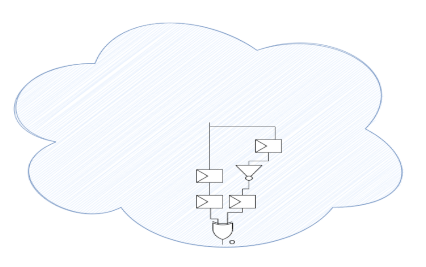
This assertion is very easy to prove. The full logic bubble may be statically covered. But the observability coverage is actually only the logic shown: 3 flops and 2 gates. The rest of the logic is not relevant to prove the property.
What did we cover on the cache controller?
Let’s consider the verification of the cache in three steps, putting the deadlock verification apart as it is very specific. We first verified that top-level interfaces are compliant with the AHB specification. Then, we verified a critical assertion checking that no multiple hits happen. Finally, we verified data integrity.
Now, let's see how this looks in terms of coverage.
Reachability coverage
We first measured reachability coverage because it is independent of the assertions. On this relatively small design it is very high. The holes are only about some dead-code. If we remove the abstractions, especially the one on the invalidation counters, this coverage goes down, confirming the usefulness of these abstractions.
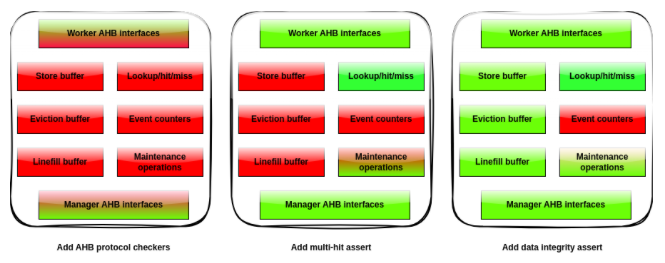
Coverages with AHB protocol checkers
After adding protocol checkers to verify the AHB compliance, static coverage was already very high. Indeed a single assertion, for example checking the stability of a data bus while waiting for a confirmation, has almost the full design in its COI. Even the logic related to maintenance operations, which we know is not directly verified by any assertion, is covered. The only holes in this metric are on the event counters.
But when looking at observability coverage, it is quite low. Indeed, the protocol assertions are very "localized", needing only the logic close to the top-level interfaces. For example, the logic handling the lookup, hit/miss computation, triggering the linefills and evictions is not covered here. This is not surprising.
Coverages with multiple hit assertions
We measured coverages again after adding the assertions checking there's no multiple hit.
Static coverage stayed the same. It was already almost at its max.
Observability coverage, however, increased significantly, especially on control dominated blocks. This is because just that assertion needs a lot of logic to be verified. This is the logic which was not covered in the previous step. But some holes remained: the event counters are still not covered, as well as the logic (not a large one, but an essential one) handling the transport of data into the design. This logic includes some muxes and buffers holding data and propagating them between different places.
Coverage with data integrity assertions
We added end-to-end assertions that verified data integrity. Again, static coverage remained the same.
Observability coverage increased a bit. Looking at the differences we could see the logic for data transport is then covered.
The only significant hole is again about event counters. This is easy to explain: there is no assertion at all about these counters. And they are not used internally by the design for anything else than providing their value outside. Using assertions and formal to verify this is probably not a good idea. It would require a tedious modeling of the conditions to hit, miss, evict, etc. This is better done with a simulation testbench.
You can build a "coverage heat-map" and update it when adding new properties, abstractions or constraints. For our cache, the heat-map representing the observability coverage would be as shown below, for the three steps we considered. The green zones are covered, the red ones are not.
So, are we done?
For this cache verification, it was safe to say "Yes". Coverage metrics showed that what we intended to verify was indeed verified. The rest is a much better candidate for simulation-based verification.
It is good to define targets for formal, and to measure them with the different coverage metrics. The added value is not really in the numbers, but in the detected holes. You have to look at them and understand whether they are expected or not. If not, improve your formal testbench, add new assertions, etc. If they are expected, you must have one or more other verification techniques to target them.
Setting a coverage target (a percentage number) does not seem like a good idea. For sure, some holes will remain in the end, and this is fine because they are covered by another verification approach. But you don't know what the relative size of these holes is.
Good practices
In this final episode we looked at ensuring that we did enough with formal. Here are some takeaways.

Wrap-up
I hope you’ve enjoyed this series where I’ve shared best practices for formal verification.
There are other formal techniques which I haven't mentioned, but which are also very useful.
For example, X-propagation verification can tell you whether you risk having bugs visible only at gate level, or even only on silicon. These bugs are particularly difficult to catch with simulation.
Sequential equivalence checking is a multi-usage tool. It can be used to verify clock-gating, ECOs, design optimization, etc. On our cache, equivalence checking has been used to ensure all the work we have done on the full cache configuration (IDCache), is valid on the Data-only configuration (DCache). For that, we compared the IDCache against the DCache, under the constraint that no request targets the Instruction part. And similarly for the Instruction-only configuration.
Security features can also be verified with formal. For a cache, it means for example, that data written as a secure request will never go out of the cache as part of a non-secure request. Vulnerabilities to side-channel attacks can also be verified with formal.
This gives us a lot of material for season 2 with more episodes!
Formally yours!
Previous episodes:
- Episode 1: Best practices to reach your targets
- Episode 2: Investigating a deadlock
- Episode 3: Towards end-to-end properties
- Episode 4: Checking data corruption
